freiesMagazin November 2016
(ISSN 1867-7991)Themen dieser Ausgabe sind u. a.
Backups in lesbarer Form irgendwo im Netz ablegen? Keine gute Idee. Backups hingegen zuerst vollständig verschlüsseln und danach auf einen beliebigen Online-Speicherplatz wegschieben? Eine gute Idee! Genau das kann Duplicity und dank Duply vereinfacht sich dessen Handhabung auf wenige, sehr einfache Befehle. (weiterlesen)Der freie Passwortmanager KeeWeb ist knapp ein Jahr nach dem Start in der Version 1.3 veröffentlicht worden. Die Applikation unterstützt unter anderem KeePass-Datenbanken und ermöglicht es, Passwörter sicher auf einem lokalen Server oder in einer Cloud zu verwalten. Wir stellen Ihnen die recht junge Anwendung vor. (weiterlesen)
„Life is Strange“ besteht aus insgesamt fünf Episoden, wovon die erste Episode kostenlos spielbar ist. Der Frage, für wen es sich lohnt, die kostenpflichtigen Episoden 2-5 dazu zu kaufen, wird in diesem Test nachgegangen. (weiterlesen)
Zum Inhaltsverzeichnis
Inhalt
Linux allgemeinDer Oktober im Kernelrückblick
Anleitungen
Verschlüsselte Server-Backups mit Duply und Duplicity
Scribus in der Praxis
Software
KeeWeb: Passwörter sicher speichern
Test: Life is Strange – Emotionale Zeitreise
Spieltipp: Don't take it personally, babe, it just ain't your story
Test: The Curious Expedition – ein Roguelike-Abenteuer für Forscher und Entdecker
Community
Rezension: Scrum
Magazin
Editorial
Veranstaltungen
Vorschau
Konventionen
Impressum
Zum Inhaltsverzeichnis
Editorial
Abschiedsgrüße
Letzten Monat kündigten wir im Editorial und auf der Webseite [1] an, dass freiesMagazin mit der Dezemberausgabe die Pforten schließt. Die Reaktion darauf war sehr positiv – also im Sinne der Anzahl, denn über 30 Leser-Reaktionen konnten wir damit erringen. Die meisten bedauerten den Schritt und bedankten sich – wofür wir uns an dieser Stelle bedanken wollen. Wir freuen uns über diese Resonanz und können die Bühne so mit dem Gefühl verlassen, dass es da draußen Menschen gab, die das Magazin genossen haben. Die Leserbriefe verschieben aber aufgrund des Umfangs auf die letzte Ausgabe, da wir denken, dass dies auch einen schönen Abschluss für das Magazin bietet. An der Stelle gab es aber eine Frage, die wir in Kürze beantworten wollen: Die Webseite soll in irgendeiner Form erhalten bleiben, sodass man mindestens weiterhin die alten freiesMagazin-Ausgaben herunterladen und anschauen kann. Wie genau wir das umsetzen, wird sich aber noch zeigen.Abo-Funktion
Pünktlich zur Verabschiedung hat uns Leser Christoph Anfang Oktober eine E-Mail zukommen lassen, dass er auf seiner Webseite [2] einen Dienst eingerichtet hat, der eine Zustellung der PDF- oder EPUB-Ausgabe von freiesMagazin per E-Mail ermöglicht. Ja, diese Funktion kommt sehr spät – wir in der Redaktion haben bisher den Aufwand gescheut, da der Bedarf laut unserer Umfrage im Juni [3] eher gering war. Dennoch Danke an Christoph für diese Möglichkeit! Sicherheitshalber aber ein Hinweis: Der Dienst stammt nicht von freiesMagazin und wir wissen auch nicht, was mit den eingegeben Daten geschieht.Letzte Chance
Wer noch einen Artikel zu freiesMagazin beitragen will, hat noch bis zum 18. November die Möglichkeit. Dann ist Redaktionsschluss für die Dezemberausgabe. Schickt Euren Artikel einfach per E-Mail an[1] http://www.freiesmagazin.de/20161002-freiesmagazin-schliesst-die-seiten
[2] http://www.monochromec.com/fm/
[3] http://www.freiesmagazin.de/20160610-separate-e-mail-abonnementen-funktion
Beitrag teilen Beitrag kommentieren
Zum Inhaltsverzeichnis
Der Oktober im Kernelrückblick
von Mathias Menzer Basis aller Distributionen ist der Linux-Kernel, der fortwährend weiterentwickelt wird. Welche Geräte in einem halben Jahr unterstützt werden und welche Funktionen neu hinzukommen, erfährt man, wenn man den aktuellen Entwickler-Kernel im Auge behält.Linux 4.8
Der Linux-Kernel 4.8 erschien Anfang Oktober nach 71 Tagen Entwicklungszeit [1]. Die vorangegangene Woche verlief recht ruhig und brachte außer ein paar letzten „Reverts“ vor dem Release, also Rücknahmen zuvor eingereichter Änderungen, hauptsächlich kleinere Fehlerkorrekturen an den x86- und MIPS- Architekturen mit. Eine der auffälligsten Änderungen – beim Blick in den Quellcode – war die Umstellung großer Teile der Kernel-Dokumentation auf Sphinx [2]. Dadurch soll die im Moment teilweise unterschiedlich gehandhabte Dokumentation besser verzahnt und damit für die Entwickler nützlicher werden. Einige Nutzer immerhin könnten von der Aufnahme eines Treibers profitieren, der die Ansteuerung von N-trig-Touchscreens erlaubt. Geräte dieses Herstellers kommen unter anderem in Microsofts Surface 3 und Surface Pro 3 zum Einsatz. Ein weiterer hinzugekommener Treiber unterstützt den Broadcom-Chipsatz BCM2837, bekannt aus dem Raspberry Pi 3. Damit können künftige Linux-System für den „Raspi“ auf Binärtreiber verzichten, zumindest soweit es rein um den Einplatinenrechner selbst geht. Im Grafikumfeld gibt es für Intel-Grafik nun Unterstützung, um virtuellen Maschinen direkten Zugang zum Grafikkern zu geben. Dies würde den virtuellen Maschinen erlauben, auf die Hardwarebeschleunigung für 3-D oder Video-Dekodierung zurückzugreifen und damit einiges an Rechenleistung der CPU sparen. Leider wird aktuell nur Intels Broadwell-Familie unterstützt und hierfür werden auch spezielle Anpassungen benötigt, die im Moment nur für KVM und Xen verfügbar sind. Ob und wann weitere Virtualisierer wie Virtualbox oder VMware in den Genuss von Unterstützung kommen und ob Linux-Distributoren ihre Pakete von KVM und/oder Xen entsprechend anpassen ist derzeit ungewiss. Die Technik „AMD Overdrive“ wird nun vom AMDGPU-Treiber unterstützt und erlaubt damit, dass AMDs Radeon-Grafikchips ohne zusätzliche Software übertaktet werden können. Für die meisten Nutzer nicht sichtbar, wurde die Verwendung von „Kernel- ASLR“ [3] ausgeweitet. Es werden nun auch 64-Bit-Systeme der verbreiteten x86-Architektur unterstützt und weitere Speicherbereiche des Kernels damit adressiert, außerdem wurden Probleme im Zusammenhang mit dem Ruhezustands-/Bereitschaftsmodus behoben. ASLR soll das gezielte Ausnutzen von Speicherüberläufen zum Ausweiten von Privilegien verhindern, indem die vom Kernel genutzten Speicherbereiche nicht an immer festen Adressen liegen, sondern zufällig „erwürfelt“ werden. Weiterhin wurden Vorbereitungen getroffen, um Kernel Stacks nicht mehr festen Adressbereichen zuzuordnen, sondern virtuell zuweisen zu können – eine Funktion, die in Linux 4.9 aufgenommen wird. Über die Vielzahl der weiteren Änderungen gibt diesmal der Artikel „Die Neuerungen von Linux 4.8“ im Kernel-Log von Heise Online [4] ausführlich Auskunft.Die Entwicklung von Linux 4.9
Das Merge Window für Linux 4.9 schloss sich diesmal einen Tag früher. Obwohl Torvalds dies hin und wieder tut, um die Entwickler zu „erziehen“, lag der Grund diesmal in der Menge der Änderungen. Tatsächlich liegt Linux 4.9-rc1 [5] mit über 15000 Änderungen sogar über den meisten Final-Versionen der letzten Jahre. Ein guten Anteil daran hat Greybus. Dabei handelt es sich jedoch nicht um einen Konkurrenten zu kdbus, das ja zur Kommunikation von Prozessen untereinander gedacht ist, sondern um einen Hardware-Bus. Greybus sollte für das zwischenzeitlich eingestampfte Projekt Ara [6] die Kommunikation der austauschbaren Hardware-Module untereinander sicherstellen. Obwohl mit Projekt Ara der Hauptgrund für die Entwicklung von Greybus nun Geschichte ist, setzen andere, darunter Motorola und Toshiba, weiterhin auf dieses System, sodass es mit Greg Kroah-Hartmann als Fürsprecher in den aktiven Kernel-Zweig aufgenommen wurde. Eine weitere bemerkenswerte Neuerung trägt den Namen „virtually mapped kernel stack allocations“. Kernel Stacks sind kleine Abschnitte innerhalb des vom Kernel reservierten Speicherbereichs, die laufenden Prozessen zugeordnet sind und von diesen genutzt werden, um Aktionen im System-Kontext vom Kernel ausführen zu lassen. Bislang waren diese Bereiche auf feste Speicheradressen adressiert, nun können sie wie virtueller Speicher verwaltet werden. Die Vorteile dabei sind, dass die Kernel Stacks nun in der Größe anpassbar sind und dass Speicherüberläufe damit erkannt und abgefangen werden können. Ausgerechnet diese Neuerung schien zuerst für einige Abstürze verantwortlich zu sein, wie Torvalds bei der Freigabe der zweiten Entwicklerversion [7] verlauten ließ. Er bat ausdrücklich darum, die Option CONFIG_VMAP_STACK zu aktivieren und an den Bemühungen zur Fehlersuche teilzunehmen. Wer dies meiden wollte, sollte diese Option jedoch ausschalten. Doch das dürfte nicht wirklich viel gebracht haben, denn als Ursache des Fehlers entpuppte sich später eine Race Condition [8] in der Warteschlange für Zugriffe auf Block Devices. Ansonsten war der Patch von Seiten der Größe her eher moderat mit lediglich 282 Commits. Neben den ersten Fehlerkorrekturen finden sich darunter auch zwei neue Treiber: ein Treiber für die IPMI-Schnittstelle [9] von AST2400- und AST2500-Prozessoren für das Management von Server-Hardware. Ein weiterer Treiber unterstützt den Hardware-Zeitgeber und seine verschiedenen Funktionsweisen der quelloffenen Prozessorplattform J-Core [10], die seit Linux 4.8 erstmals unterstützt wird. Das Besondere an J-Core ist, dass sich diese Prozessoren mittels frei programmierbarer FPGA [11] selbst „bauen“ lassen. Linux 4.9-rc3 [12] brachte in erster Linie die zuvor erwähnte Kenntnis, dass VMAP_STACK nicht die Ursache der Probleme bei -rc2 war und der Fehler wohl jenseits gezielter Stresstests eher nicht aufgetaucht sein dürfte. Ansonsten fiel die aktuelle Entwicklerversion relativ übersichtlich aus. So brachte sie in erster Linie Korrekturen mit, insbesondere für die erst jüngst eingeführten Reflinks im Dateisystem XFS. Diese ermöglichen schnelle „Kopiervorgänge“ großer Dateien, indem lediglich ein neuer Satz an Metadaten angelegt und auf das Ausgangsobjekt verwiesen wird. Links[1] https://lkml.org/lkml/2016/10/2/102
[2] http://www.sphinx-doc.org
[3] https://de.wikipedia.org/wiki/Address_Space_Layout_Randomization
[4] http://heise.de/-3283402
[5] https://lkml.org/lkml/2016/10/15/112
[6] https://de.wikipedia.org/wiki/Project_Ara
[7] https://lkml.org/lkml/2016/10/23/203
[8] https://de.wikipedia.org/wiki/Race_Condition
[9] https://de.wikipedia.org/wiki/Intelligent_Platform_Management_Interface
[10] http://j-core.org/
[11] http://xkcd.com/456/
[12] https://de.wikipedia.org/wiki/Copy-On-Write
[13] https://lkml.org/lkml/2016/10/29/405
Autoreninformation |
| Mathias Menzer (Webseite) behält die Entwicklung des Linux-Kernels im Blick, um über kommende Funktionen von Linux auf dem Laufenden zu bleiben. und immer mit interessanten Abkürzungen und komplizierten Begriffen dienen zu können. |
Beitrag teilen Beitrag kommentieren
Zum Inhaltsverzeichnis
Verschlüsselte Server-Backups mit Duply und Duplicity
von David Schroff Backups in lesbarer Form irgendwo im Netz ablegen? Keine gute Idee. Backups hingegen zuerst vollständig verschlüsseln und danach auf einen beliebigen Online-Speicherplatz wegschieben? Eine gute Idee! Genau das kann Duplicity [1] und dank Duply [2] vereinfacht sich dessen Handhabung auf wenige, sehr einfache Befehle. Duplicity erlaubt die Erstellung voller und inkrementeller Backups verschlüsselt auf ganz unterschiedliche Backup-Speicherplätze. Zum Beispiel auf einen beliebigen FTP-Server, per Webdav oder SSH/SCP auf einem Backup-Server, in die Amazon S3 Cloud oder sogar auf einen Online-Speicherplatz wie Dropbox und Megaupload. Dank der GPG-Verschlüsselung noch bevor das Backup den eigenen Server verlässt, ist ein Datenklau so gut wie ausgeschlossen. Eine vollständige Liste der unterstützten Dienste findet sich auf der Duplicity-Projektseite [1]. Duply und Duplicity besitzen keine grafische Oberfläche und eignen sich deshalb vor allem für automatisierte Server-Backups. Für den Desktop gibt es das Werkzeug Déjà Dup [3], das mit einer grafischen Oberfläche ebenfalls auf Wunsch verschlüsselte Backups erstellt.Duply in der Praxis
Duply dient als Wrapper für Duplicity und reduziert die Handhabung von Sicherung und Wiederherstellung auf das Nötigste. Die folgenden Beispiele verdeutlichen die Einfachheit von Duply:
// Status der vollen und inkrementellen
// Backups anzeigen
# duply mybackupprofile status
// Backup erstellen
# duply mybackupprofile backup
// Aktuell gelöschten Pfad
// wiederherstellen, vor 3 Tagen
# duply mybackupprofile restore /tmp 3D
// Einzelne Datei wiederherstellen,
// unter neuem Namen abspeichern, aus
// dem letzten Backup
# duply mybackupprofile fetch etc/passwd /tmp/passwd_restored
// Einen Ordner wiederherstellen, unter
// neuem Namen abspeichern, vor 7 Tagen
# duply mybackupprofile fetch etc /tmp/etc_folder_restored 7D
// Backups anzeigen
# duply mybackupprofile status
// Backup erstellen
# duply mybackupprofile backup
// Aktuell gelöschten Pfad
// wiederherstellen, vor 3 Tagen
# duply mybackupprofile restore /tmp 3D
// Einzelne Datei wiederherstellen,
// unter neuem Namen abspeichern, aus
// dem letzten Backup
# duply mybackupprofile fetch etc/passwd /tmp/passwd_restored
// Einen Ordner wiederherstellen, unter
// neuem Namen abspeichern, vor 7 Tagen
# duply mybackupprofile fetch etc /tmp/etc_folder_restored 7D
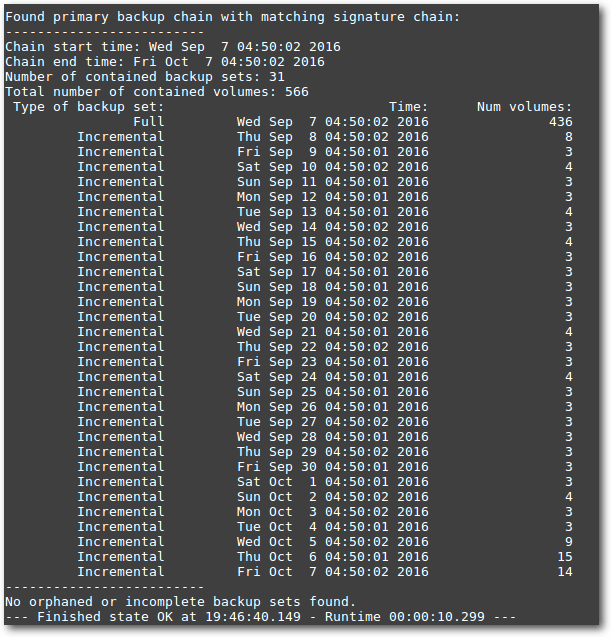
Status von Duplicity.
Tipp: Der Pfad im Backup muss ohne beginnendes Slash angegeben werden, also etc anstatt /etc. Duply bietet natürlich noch weitere Befehle zur Verwaltung eines Backups an. Eine Übersicht aller Möglichkeiten kann mit # duply usage aufgerufen werden. Die Ausführungen der Backups werden per Cronjob angelegt, einen Daemon gibt es nicht. Es können auch gleich mehrere Befehle mit einem Verbindungsstrich hintereinander gelegt werden; so reduziert sich eine Sicherung mit Verifizierung und Löschung nicht mehr benötigter, alter Backups auf eine Zeile, hier am Beispiel eines täglichen Backups um 04:30 Uhr:
30 4 * * * /usr/local/bin/duply mybackupprofile backup_verify_purge --force
Ob Duply damit ein volles oder inkrementelles Backup erstellt, entscheidet das
Programm anhand der Einstellungen in der conf-Datei. Neben dieser
Konfiguration beachtet Duply im selben Verzeichnis die optionalen Dateien
exclude, include, pre und post.
Duply und Duplicity installieren
Duply sowie Duplicity können im Repository der verwendeten Linux-Distribution vorliegen, sie sind aber höchstwahrscheinlich veraltet. Die Entwicklung von Duply und Duplicity geht auch 2016 weiter; es empfiehlt sich daher, eine aktuelle Version der beiden Werkzeuge zu installieren. Als Vorbereitung zur Duplicity-Installation müssen mindestens folgende Pakete installiert werden:- python-dev
- librsync-dev
- ncftp
- lftp
# python setup.py install
Damit ist die Duplicity-Installation abgeschlossen. Als nächstes wird Duply von
deren Projekt-Webseite [2] auf den Server nach
/usr/local/bin/duply kopiert und ausführbar gemacht. Duply selbst besteht aus
einem einzigen Bash-Script mit über 2300 Zeilen.
# chmod u+x /usr/local/bin/duply
Als letzter Schritt muss zwingend ein GPG-Schlüssel erstellt werden, denn ohne
Schlüsselpaar gibt es kein verschlüsseltes Backup. Eine interaktive
Schlüssel-Erstellung wird so gestartet:
# gpg --gen-key
Die Schlüssel-Erstellungsroutine stellt einige Fragen und erzeugt anschließend
das Schlüsselpaar. Ein Schlüssel mit 2048 Bit gilt derzeit noch als sicher. Die
anderen auszufüllenden Angaben sind selbsterklärend.
Tipp: Auf Servern, auf denen „nichts los ist“, kann die Erstellung eines großen
Schlüssels lange dauern. Eine Umgehungslösung wäre, vorher das Programm
„haveged“ [5] zu installieren. Haveged befüllt das System direkt nach der
Installation immerzu mit mehr zufälliger Entropy und ist in den meisten
Distributionspaketquellen enthalten.
GPG wird dem Schlüssel eine zufällige Bezeichnung vergeben, diese
Schlüssel-Bezeichnung muss im nächsten Schritt in der Duply-Konfiguration mit
angegeben werden. Die Ausgabezeile wird beispielsweise so aussehen:
gpg: key 275A04C3 marked as ultimately trusted
Alternativ kann mittels gpg --list-keys die vorhin erstellte
Schlüsselbezeichnung aufgerufen werden.
Tipp: Zwei Dinge sind bei einem Komplettverlust des Servers ab jetzt
überlebenswichtig: Das Schlüssel-Passwort und das generierte
Schlüsselpaar selbst. Das Passwort muss man sich natürlich gut merken,
die Schlüsseldateien müssen gesichert werden. Letzteres kann etwas
später erledigt werden: Duply legt die Schlüsselpaare im Profilordner
als Dateien ab, nachdem ein erstes Backup durchgeführt worden ist. Also
sichert man sich den kompletten Duply-Profilordner nach der ersten
Sicherung separat.
Tipp: GPG-Keys können auch als Batch vollautomatisch erstellt
werden. Dieses Vorgehen lohnt sich, wenn Duply/Duplicity auf mehrere
Server automatisiert ausgerollt werden soll. Hierzu benötigt man das
Kommando gpg –gen-key --batch /tmp/gpg_property_datei. Die
zwingend benötigten Angaben der Batch-Datei können auf GnuGPG.org
nachgelesen [6]
werden. Hier ein Beispiel:
Key-Type: 1
Key-Length: 2048
Subkey-Type: 1
Subkey-Length: 2048
Name-Real: Duply-GPG-Key
Name-Email: root@localhost
Expire-Date: 0
Passphrase: MEINPASSWORT
Der nachfolgende Befehl erstellt das Duply-Backupprofil. Der Name kann frei
gewählt werden und lautet in diesem Beispiel mybackupprofile:
Key-Length: 2048
Subkey-Type: 1
Subkey-Length: 2048
Name-Real: Duply-GPG-Key
Name-Email: root@localhost
Expire-Date: 0
Passphrase: MEINPASSWORT
# duply mybackupprofile create
Duply generiert damit einen Profilordner unter
/root/.duply/mybackupprofile.
Duply konfigurieren
Die Datei /root/.duply/mybackupprofile/conf ist eine benutzbare Vorlage für die Konfigurationsdatei und wird jetzt für die eigenen Bedürfnisse angepasst. Es müssen einzelne Zeilen einkommentiert werden, das #-Zeichen zu Beginn der Zeilen muss also entfernt werden.
GPG_KEY='275A04C3'
GPG_PW='MeinPasswort'
TARGET='ftp://benutzername:passwort@hostname.com:21/mybackupprofile'
SOURCE='/'
FILENAME='.duplicity-ignore'
DUPL_PARAMS="$DUPL_PARAMS --exclude-if-present '$FILENAME'"
MAX_AGE=1M
MAX_FULL_BACKUPS=2
MAX_FULLBKP_AGE=1M
DUPL_PARAMS="$DUPL_PARAMS --full-if-older-than $MAX_FULLBKP_AGE "
VOLSIZE=25
DUPL_PARAMS="$DUPL_PARAMS --volsize $VOLSIZE "
Diese Beispielkonfiguration erstellt ein Backup auf einen FTP-Server mit
einigen Eigenschaften:
GPG_PW='MeinPasswort'
TARGET='ftp://benutzername:passwort@hostname.com:21/mybackupprofile'
SOURCE='/'
FILENAME='.duplicity-ignore'
DUPL_PARAMS="$DUPL_PARAMS --exclude-if-present '$FILENAME'"
MAX_AGE=1M
MAX_FULL_BACKUPS=2
MAX_FULLBKP_AGE=1M
DUPL_PARAMS="$DUPL_PARAMS --full-if-older-than $MAX_FULLBKP_AGE "
VOLSIZE=25
DUPL_PARAMS="$DUPL_PARAMS --volsize $VOLSIZE "
- Der Backup-Job wird alle Ordner/Dateien unterhalb / (Rootpfad) sichern, mit Ausnahme der angegebenen Pfade in der exclude-Datei.
- Monatlich wird ein Full-Backup angestoßen, wovon maximal 2 vorhanden sein müssen.
- Alle Ordner und dessen Unterordner, der die leere Datei .duplicity-ignore enthält, werden vom Backup-Job ignoriert.
- Das Backup wird auf dem Ziel-FTP in 25 MB Häppchen abgelegt.
- /sys
- /dev
- /proc
- /tmp
# duply mybackupprofile backup
Duply GPG-Schlüssel sicher verwahren & Disaster Recovery
Ohne Schlüssel und ohne Passwort ist eine Wiederherstellung der Datensicherung unmöglich! Aus diesem einfachen Grund speichert man jetzt den kompletten Duply-Profilordner weg: /root/.duply/mybackupprofile. Darin enthalten sind auch die zwingend benötigten GPG-Schlüssel, welche Duply mit der ersten Datensicherung automatisch exportiert hat. Eine Vorgehensweise könnte sein, ein TAR-Archiv zu erstellen, dieses wiederum mit gpg -c meinArchiv.tar mit einem GPG-Passwort zu versehen und an mehreren Orten weit weg vom Server abzuspeichern. Falls tatsächlich einmal die Festplatte irreparabel zerstört wird, kann der Profilordner unter /root/.duply/mybackupprofile in die frische Systeminstallation hineinkopiert werden. GPG muss die Schlüssel der Sicherungen kennen und ihnen vertrauen. Das Einlesen der GPG-Keys in den sogenannten GPG-Keyring gelingt mit --import:
# gpg --import /root/.duply/mybackupprofile/gpgkey.275A04C3.sec.asc
# gpg --import /root/.duply/mybackupprofile/gpgkey.275A04C3.pub.asc
Danach muss dieser Schlüssel noch als „ultimately trusted“
markiert werden, denn sonst würde Duply bei der Wiederherstellung mit
einer Fehlermeldung abbrechen:
# gpg --import /root/.duply/mybackupprofile/gpgkey.275A04C3.pub.asc
# gpg --edit-key '275A04C3'
# trust
# 5 = I trust ultimately
Ab diesem Zeitpunkt kann die Datensicherung mit den üblichen
Befehlen duply mybackupprofile restore oder
duply mybackupprofile fetch wiederhergestellt werden.
Tipp: Duplys Datensicherung ist dateibasiert, es weiß also nicht,
welche RPM/DEB-Pakete installiert sind. Es erstellt auch keine
Mysqldumps selbstständig. Daher lohnen sich in der Praxis zweierlei
Dinge: Erstens täglich eine Text-Datei erstellen und in die Sicherung
inkludieren, worin die Information aller installierten RPM/DEB-Pakete
abgelegt sind. Zweitens das unter Debian beliebte Paket automysqlbackup
installieren, womit sofort und ohne Konfigurationsaufwand täglich ein
Mysqldump aller Datenbanken unter /var/lib/automysqlbackup erstellt
wird.
# trust
# 5 = I trust ultimately
Nachteile von Duply in der Praxis
Duply macht vieles richtig: es vereinfacht Duplicity auf angenehme Weise, die Benutzung geht leicht von der Hand und eine Sicherung sowie Wiederherstellung funktioniert. Leider aber ist Duply/Duplicity von Grund auf nicht die schnellste Backup-Variante: Hardlinks werden nicht unterstützt, Backup und Restore brauchen durch die Ver- und Entschlüsselung natürlich etwas mehr Zeit und in aller Regel ist der verwendete Backup-Speicherplatz auch noch ein langsam erreichbarer FTP- oder Cloudstorage. Eine vollständige Sicherung von 200 GB auf einen langsamen FTP kann durchaus mehrere Stunden dauern. Der Restore für einzelne Dateien dauert, je weiter weg das letzte Full-Backup war, zwischen 20 Sekunden bis zu 10 Minuten. Für extrem zeitkritische Wiederstellung ist Duply/Duplicity also eher die zweite Wahl. Daher sollte man zunächst die Wiederherstellung einzelner Dateien oder kompletter Ordner testen. Ein weiterer Nachteil sind die noch nicht ausgereiften Status-Abfragen. Es gibt zwar mit dem Kommando duply mybackupprofile list eine Ausgabe aller Dateien im Backup, diese lässt sich aber nicht auf einzelne Dateien und deren verschiedenen Versionen eingrenzen. In der Praxis ist das eher selten gewünscht, insofern bleibt dieser Nachteil mehr eine kosmetische Sache. In die gleiche Kerbe schlägt die fehlende Anzeige, wie groß eine einzelne Sicherung tatsächlich ist. Die Angabe der Größe gibt Duply in Volumes an, nicht etwa in Megabyte oder Gigabyte. Duply holt sich für die Wiederherstellung des letzten, inkrementellen Backups alle Dateiversionen seit der letzten vollständigen Sicherung. Damit besteht die Gefahr, dass bei einer korrupten Backup-Ablage der ganze Rattenschwanz an inkrementellen Backups unbrauchbar wird. In der Theorie wird darauf hingewiesen, in der Praxis dürfte das nicht wirklich passieren. Links[1] http://duplicity.nongnu.org/
[2] http://duply.net/
[3] https://wiki.ubuntuusers.de/Déjà_Dup/
[4] http://duplicity.nongnu.org/duplicity.1.html#toc30
[5] http://www.issihosts.com/haveged/
[6] https://www.gnupg.org/documentation/manuals/gnupg/Unattended-GPG-key-generation.html
Autoreninformation |
| David Schroff (Webseite) verwendet Duply/Duplicity auf seinen Web-Servern seit fünf Jahren. |
Beitrag teilen Beitrag kommentieren
Zum Inhaltsverzeichnis
Scribus in der Praxis
von Holger Reibold Es ist hinlänglich bekannt, dass Scribus ein hervorragendes DTP-Programm ist, das sich durchaus mit kommerziellen Produkten wie InDesign & Co. messen kann. Scribus stellt eine Fülle an Funktionen für das Gestalten und Bearbeiten von Texten und sonstigen Elementen zur Verfügung. Man muss sie nur effektiv einzusetzen verstehen. Auf den ersten Blick ist auch nicht ersichtlich, dass man auch ein Inhaltsverzeichnis anlegen kann – allerdings nicht so komfortabel wie bei Textverarbeitungsprogrammen. Dieser Artikel stellt verschiedene Möglichkeiten für den Praxiseinsatz von Scribus vor. Wenn man einen Textrahmen anlegt und diesen mit ersten Eingaben füllt oder einen Text in den Textrahmen lädt, verwendet Scribus die Formatierungen, die man mit dem „Eigenschaften“-Dialog vorgenommen hat. Doch in der Praxis erweist sich die Gestaltung als sehr mühsam und umständlich. Zum Glück hat Scribus auch hierfür das passende Werkzeug: den Story Editor.Der Story-Editor
Der Story-Editor ist eine Art abgespeckter Editor, der alle wichtigen Funktionen für die Formatierung von Textbausteinen bietet. Der Aufruf des Story Editors erfolgt über das Menü „Bearbeiten -> Text bearbeiten“, mit der Tastenkombination „Strg“ + „T“ oder aus dem Kontextmenü des Textrahmens mit „Text bearbeiten“.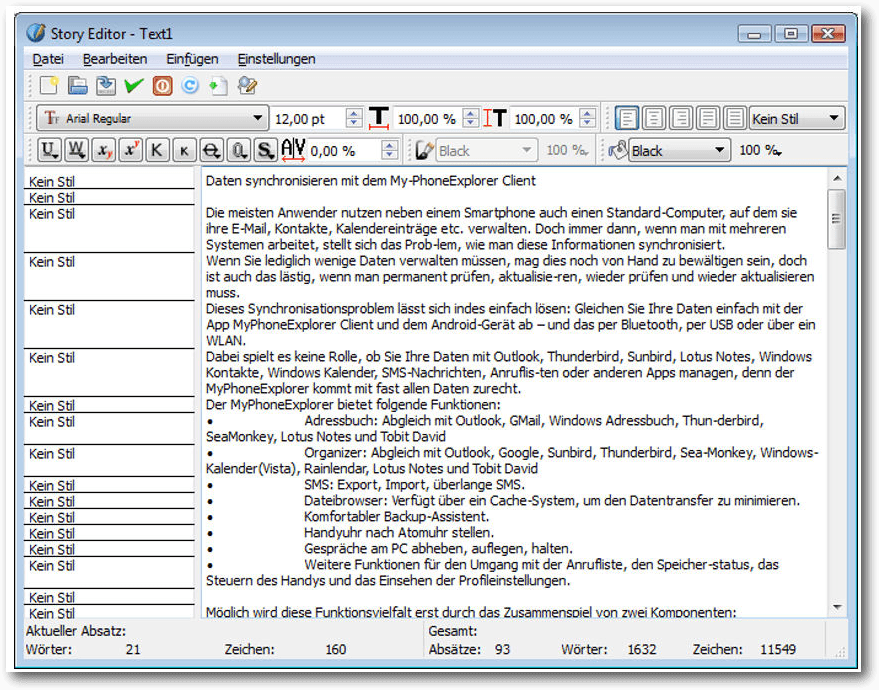
Der Story Editor in Aktion.
In der Kopfzeile zeigt er den Titel des Textrahmens an. Darunter findet man die Menü- und die Symbolleiste. Die Menüleiste stellt eine Fülle von nützlichen Funktionen zur Verfügung. Mit dem Befehl „Datei -> Text entfernen“ kann man den im Editor geladenen Text löschen. Wenn man den Text an anderer Stelle weiterverwenden möchte, führt man den Befehl „Datei -> In Datei speichern“ aus und bestimmt im „Speichern“-Dialog das Zielverzeichnis. Auf diesem Weg kann man Texte der Textrahmen einfach und unkompliziert als Textdatei sichern. Auch das Laden von anderen Texten ist über das „Datei“-Menü möglich. Im „Bearbeiten“-Menü findet man typische Funktionen für das Kopieren, Ausschneiden und Einfügen. Hier findet man auch die Suchen und Ersetzen-Funktion. Aus dem Story Editor kann man außerdem mit dem Befehl „Bearbeiten -> Schriftvorschau“ auf den gleichnamigen Dialog zugreifen, mit dem man sich einen Überblick über das Schriftbild unbekannter Schriften verschafft. Ein weiteres Highlight des Story Editors ist das „Einfügen“-Menü. Hier stehen unzählige Symbole und Zeichen zur Verfügung, die man in seinen Texten verwenden kann, beispielsweise verschiedene Schrägstrichvarianten, Anführungszeichen, Leerzeichen und Ligaturen. Im Menü „Einstellungen“ kann man außerdem die Hintergrundfarbe ändern. Diese Änderung bezieht sich lediglich auf die Darstellung im Editor, nicht aber auf den Textrahmen selbst.
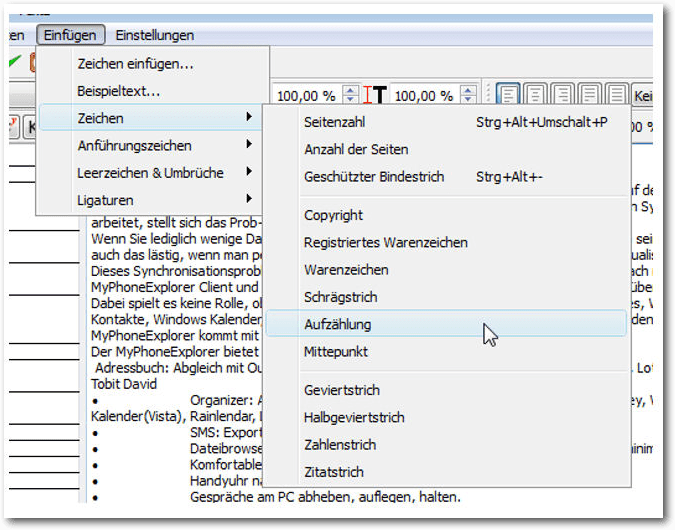
Das Einfügen von unterschiedlichen Zeichen und Symbolen.
Die wichtigsten Funktionen des Editors sind über die Symbolleiste verfügbar. Hier stehen folgende Funktionen zur Verfügung (von links nach rechts):
- Text entfernen
- Von Datei laden
- In Datei speichern
- Änderungen übernehmen
- Änderungen ignorieren
- Text neu von Textrahmen
- Textrahmen auffrischen
- Suche und Ersetzen
- Schrift verändern
- Stil verändern
- Zeicheneinstellungen bearbeiten
- Umrissfarbe verändern
- Füllfarbe verändern
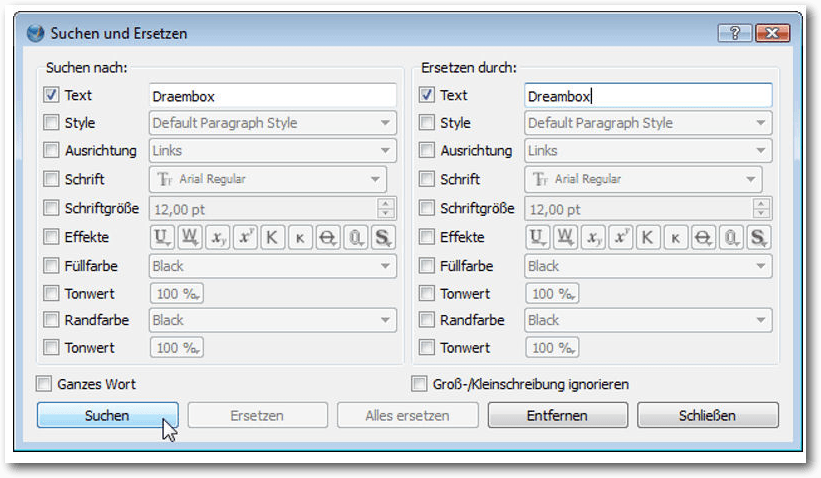
Der Dialog „Suchen und Ersetzen“ des Story Editors.
Hat man in der Stilverwaltung von Scribus verschiedene Stile angelegt, kann man im Story Editor einfach auf die angelegten Stilkonfigurationen zurückgreifen. Der Story Editor präsentiert unterhalb der Leisten den Bearbeitungsbereich für die Texte. Links findet man die Stil-Leiste, mit der man jedem Absatz einen verfügbaren Stil zuweist. Um den Absatzstil zu ändern, klickt man links auf die entsprechende Dokumenthöhe und wählt dann aus dem Pop-up-Dialog den gewünschten Stil aus. Innerhalb des Textbereichs kann man mithilfe der rechten Maustaste einige Funktionen wie das Rückgängigmachen, Kopieren, Ausschneiden, Löschen und alles Auswählen ausführen. Im unteren Bereich des Story Editors findet man die Statusleiste. Die ist zweigeteilt und verrät links, wie viele Wörter und Zeichen der aktuelle Absatz umfasst. Rechts erfährt man, wie viele Absätze, Wörter und Zeichen das gesamte Dokument besitzt.
Inhaltsverzeichnis erstellen
Mit den Stilfunktion und dem Story Editor verfügt Scribus über wichtigste Werkzeuge für das Erstellen, Bearbeiten und Gestalten von Texten. Doch Scribus hat noch weit mehr zu bieten. So kann man beispielsweise ein Inhaltsverzeichnis generieren, die Silbentrennung verwenden oder Text automatisch formatieren. Will man eine umfangreiche Broschüre oder sogar ein Buch mit Scribus gestalten, benötigt das Dokument in der Regel auch ein Inhaltsverzeichnis. Von Textverarbeitungen wie MS Word oder OpenOffice Writer bzw. LibreOffice Writer weiß man, dass es keine Hexerei ist, ein umfangreiches Dokument samt Inhaltsverzeichnis erzeugen. Ganz so einfach ist es allerdings bei Scribus nicht. Anhand eines sehr einfachen Beispiels zeigt der folgende Abschnitt, wie man in Scribus ein Inhaltsverzeichnis generieren kann.- Zunächst legt man ein mehrseitiges Dokument an oder öffnet ein bestehendes.
- Auf der ersten Seite erzeugt man drei Textrahmen, einen für den Dokumententitel, einen für das kommende Inhaltsverzeichnis und einen für die ersten Absätze des Dokuments.
- Dann weist man den verschiedenen Textrahmen eine Bezeichnung zu. Den zweiten Rahmen bezeichnet man über den „Eigenschaften“-Dialog beispielsweise mit „Inhaltsverzeichnis“.
- Dann ruft man die Eigenschaften des Dokumentenobjekts mit dem Befehl „Datei -> Dokument einrichten -> Eigenschaften des Dokumententyps“ auf und erzeugt ein neues Attribut. Dann klickt man die Schaltfläche „Hinzufügen“, dann in das Feld „Wert“ und bestätigen den Eintrag mit „OK“.
- Dann führt man den Menübefehl „Datei -> Dokument einrichten -> Inhaltsverzeichnisse“ aus. Dort klickt man auf die Schaltfläche „Hinzufügen“, um ein neues Inhaltsverzeichnis anzulegen.
- Als Nächstes bestimmt man im Auswahlmenü „Bezeichnung“ des Dokumentenobjekts das Objekt, in diesem Fall besitzt es die Bezeichnung „Inhaltsverzeichnis“. Dann ordnet man dem Verzeichnis im Auswahlmenü „Zielrahmen“ den Eintrag „Inhaltsverzeichnis“ zu. Die Eingaben bestätigt man mit „OK“.
- Dann markiert man den zweiten Textrahmen mit der rechten Maustaste und führt den Befehl „Attribute“ aus. Scribus präsentiert das Fenster „Eigenschaften des Seitenobjekts“. Man klickt auf „Hinzufügen“ und wählt im Auswahlmenü „Name“ den Eintrag „Inhaltsverzeichnis“ aus. In das Feld „Wert“ gibt man den Eintrag im Inhaltsverzeichnis an.
- Entsprechend geht man mit den weiteren Seiten vor und erzeugt dort jeweils weitere Einträge für das Inhaltsverzeichnis.
- Hat man alle Textrahmen entsprechend markiert, fügt man das Inhaltsverzeichnis an der gewünschten Position ein. Dazu platziert man den Cursor in dem dafür vorgesehenen Textrahmen und führt den Menübefehl „Extras -> Inhaltsverzeichnis“ erstellen aus.
- Scribus fügt das Inhaltsverzeichnis in den gewünschten Textrahmen ein. Man kann sich dann an die Bearbeitung des Verzeichnisses machen und beispielsweise verschiedene Absatzstile testen.
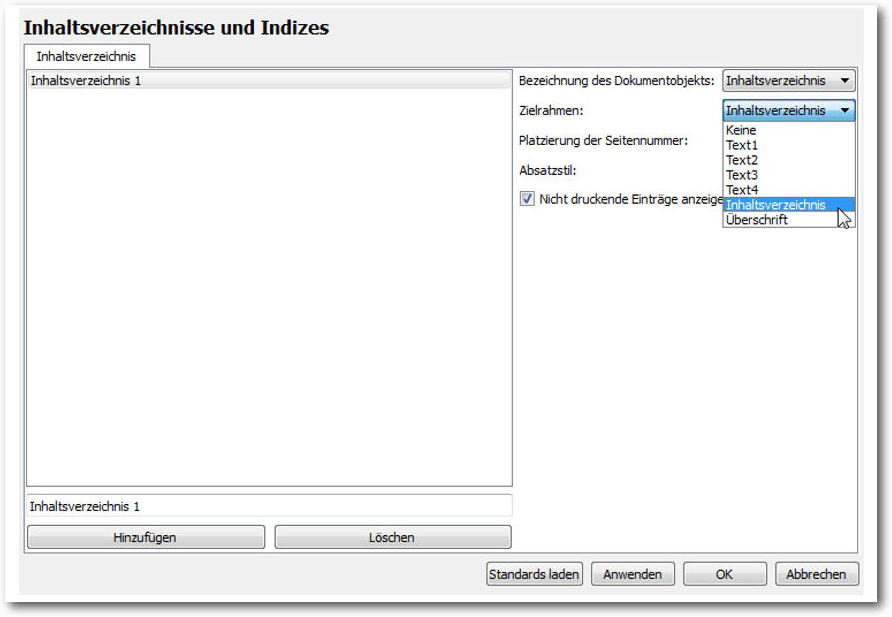
Die Zuweisung von Inhaltsverzeichnis und Dokumentobjekt sowie Zielrahmen.
Silbentrennung
Die Silbentrennung ist ein sehr wichtiges typografisches Gestaltungsmittel, mit dem man den in den Textrahmen zur Verfügung stehenden Raum optimal ausnutzen kann. Die Silbentrennung folgt festen orthografischen Regeln und kann in Scribus automatisiert durchgeführt werden. Die Silbentrennung ist ein nützliches Hilfsmittel, um die Lesbarkeit und das Erscheinungsbild von Texten zu optimieren. Unschöne Lücken werden so durch Text gefüllt und es ergibt sich in der Regel ein deutlich besseres Gesamtbild. In den Programmeinstellungen kann man die Silbentrennung konfigurieren und an die jeweiligen Bedürfnisse anpassen. Man kann die Einstellungen für die Silbentrennung programmweit, aber auch individuell für jedes Dokument festlegen. Die dokumentenspezifischen Einstellungen sind über das Menü „Datei -> Dokument einrichten -> Silbentrennung“ verfügbar. Besonders wichtig bei den dokumentbezogenen Einstellungen ist, dass man die Sprache des Dokuments korrekt einrichtet. Wenn man also mit Scribus Dokumente in unterschiedlichen Sprachen erstellt, sollte man auf die korrekte Sprachkonfiguration achten. In den Programm- bzw. Dokumenteneinstellungen kann man eigene Vorschläge hinterlegen, wie bestimmte Wörter zu trennen sind. Um die Silbentrennung auf den aktuellen Textrahmen anzuwenden, markiert man diesen und führt den Menübefehl „Extras -> Silbentrennung anwenden“ aus. Dabei ist zu beachten, dass die Trennung immer nur auf den markierten Textrahmen angewendet wird. Man kann also für einen Rahmen die Silbentrennung verwenden und bei anderen auf die Trennung verzichten.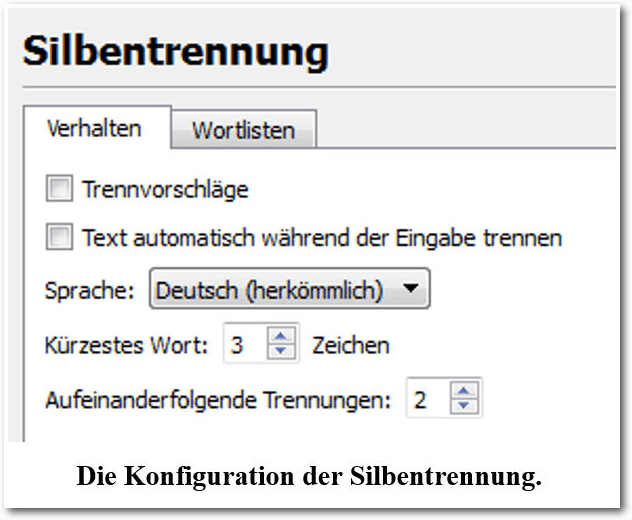
Die Konfiguration der Silbentrennung.
Text über Textfilter formatieren
Scribus bietet verschiedene Möglichkeiten für die Textformatierung. Besonders bequem und komfortabel: Man kann vorbereitete Texte mithilfe eines Textfilters formatieren. Da in Scribus die unterschiedlichsten Ausgangsdokumente, genauer deren Inhalte verwendet werden, ist es besonders hilfreich, wenn man den Import mit speziellen Filtern automatisieren kann. Das Grundprinzip dabei: Man führt im zu importierenden Text speziellen Markierungen, sogenannte Tags ein (wie man sie von HTML-Dokumenten kennt), die dann entsprechend von Scribus verarbeitet werden. Will man zudem in Dokumenten ein identisches Layout verwenden, ist es ratsam, eine Vorlage anzulegen, die bestimmte Vorgaben z. B. die Formatierung von Absätzen, Überschriften etc. macht. In der Praxis kann man beispielsweise eine Vorlage mit drei Vorgaben anlegen: „Ü1“, „A1“ und „A2“. Bei „Ü1“ handelt es sich um die Überschrift erster Ebene, bei „A1“ und „A2“ um zwei unterschiedliche Absatzformate. Das Dokument mit diesen Voreinstellungen speichert man über das „Datei“-Menü als Vorlage. Als Nächstes macht man sich an die Bearbeitung des Textes, den man mit dem Filter verarbeiten möchte. Hierfür definiert man verschiedene Tags:- \U1 – Absatzstil, der die erste Überschrift formatiert
- \A1 – Absatzstil, der den ersten Absatz des Fließtextes formatiert
- \A2 – Absatzstil, der alle weiteren Absätze des Fließtextes formatiert
Fazit
Scribus genügt längst semi-professionellen Anforderungen im DTP-Bereich. Das Programm bietet mit dem Story Editor ein komfortabler Werkzeug für das Bearbeitung und Formatieren von Texten. Auch die Verwendung der Silbentrennung ist einfach. Ein wenig umständlich gestaltet sich das Erstellen von Inhaltsverzeichnissen. Doch dafür kann man Formatierungen auch weitgehend automatisieren – man muss nur wissen, wie es geht.Autoreninformation |
| Holger Reibold (Webseite) promovierte in Informatik und begann in den 1990ern seine Karriere als Fachjournalist und Autor. Er veröffentlichte seitdem zahlreiche Artikel und Bücher. 2005 gründete er den Verlag Brain-Media.de. |
Beitrag teilen Beitrag kommentieren
Zum Inhaltsverzeichnis
KeeWeb: Passwörter sicher speichern
von Mirko Lindner Der freie Passwortmanager KeeWeb ist knapp ein Jahr nach dem Start in der Version 1.3 veröffentlicht worden. Die Applikation unterstützt unter anderem KeePass-Datenbanken und ermöglicht es, Passwörter sicher auf einem lokalen Server oder in einer Cloud zu verwalten. Wir stellen Ihnen die recht junge Anwendung vor. Redaktioneller Hinweis: Der Artikel „Keeweb: Passwörter sicher speichern“ erschien erstmals bei Pro-Linux [1].Allgemein
KeePass [2] gehört zu den bekanntesten Passwortmanagern unter Windows. Die Lösung verschlüsselt die gesamte Datenbank, welche unter anderem Benutzernamen oder Passwörter in Klartext enthalten kann. Die Datenbank selbst kann wiederum durch einen Hauptschlüssel gesichert werden, der zwingend zur Entschlüsselung eingegeben werden muss. Zudem kann auch eine Schlüsseldatei benutzt werden, die separat auf einem mobilen Medium gespeichert werden sollte. Der Schlüssel und die Schlüsseldatei bilden bei gleichzeitiger Benutzung einen gemeinsamen Schlüssel, was die Entropie des Schlüssels erhöht und die Lösung noch besser gegen Angriffe schützt.
Der freie Passwortmanager KeeWeb.
Während KeePass1, auch „Classic“ genannt, unter Linux nur auf Umwegen installiert werden konnte, unterstützt die zweite Version das freie Betriebssystem durchgehend. Grund dafür ist die Implementierung in C# und die damit einhergehende Portabilität mittels Mono. Wer allerdings weder Mono noch die teils gewöhnungsbedürftige Oberfläche einsetzen will, ist auf Fremdanwendungen, wie beispielsweise KeePassX [3] oder KeePassC [4], angewiesen. Mit KeeWeb existiert aber auch eine freie Alternative, die nicht nur die Datenbank von KeePass2 lesen kann, sondern auch durch eine Plattformunabhängigkeit und eine leichte Bedienung überzeugen will.
Erste Schritte mit KeeWeb
KeeWeb ist, wie der Name bereits suggeriert, eine Webanwendung und wird sowohl im Quellcode wie auch in Form eines selbst gehosteten Pakets angeboten. In der Praxis bedeutet das, dass die Lösung entweder lokal auf einem Desktop oder aber auf einem Server installiert werden kann. Als Ablage für Datenbanken unterstützt KeeWeb verschiedene Dienste, darunter eine lokale Speicherung oder verteilte Ablage in der Cloud. Das Programm lädt dabei die Datenbank automatisch herunter, speichert darin verschlüsselt die gewünschten Informationen und lädt die geänderten Daten wieder autark auf den Server hoch. Die Installation von KeeWeb kann auf dreierlei Arten erfolgen. Zum einen kann die Lösung bereits vorkompiliert heruntergeladen und lokal als sogenannte Desktop-Anwendung gestartet werden, zum anderen kann sie als Service auf dem Server des Autors eingesetzt werden. Eine dritte Möglichkeit ist die Installation auf einem eigenen Server, die sich ebenso als recht unkompliziert erweist. Dazu reicht es, die Daten der Lösung herunterzuladen und die bereitgestellte index.html-Datei auf die entsprechende Stelle auf dem hauseigenen Web-Server zu kopieren:
# git clone https://github.com/keeweb/keeweb.git
# cd keeweb/
# git checkout -t origin/gh-pages
# cp index.html /SERVER_HTML/
# chown WWWUSER /SERVER_HTML/index.html
# chmod 600 /SERVER_HTML/index.html
Wer dagegen KeeWeb lieber selbst aus den Quellen kompilieren möchte, muss ein wenig mehr
Mühe in die Installation investieren und benötigt unter anderem nodejs, npm und
grunt. grunt-cli kann mit dem Kommando npm install grunt-cli -g
global installiert werden. Zudem müssen noch diverse Module installiert sein,
damit das grunt-Kommando das Paket korrekt bilden kann. Das fertige Paket findet
sich nun im Verzeichnis
dist.
# cd keeweb/
# git checkout -t origin/gh-pages
# cp index.html /SERVER_HTML/
# chown WWWUSER /SERVER_HTML/index.html
# chmod 600 /SERVER_HTML/index.html
Datenablage
Ja nach Art wird dann KeeWeb entweder mittels des Kommandos ./KeeWeb (Desktop-Anwendung) oder durch das Aufrufen von index.html (Web-Service) gestartet. Die Oberfläche der Anwendung unterscheidet sich dabei nicht wirklich. Was sich allerdings unterscheidet, ist die Art der Datenspeicherung. Denn KeeWeb selbst unterscheidet, von welcher Stelle die Anwendung aufgerufen wurde. Wurde KeeWeb als Desktop-App erstellt und gestartet, ermöglicht die Lösung eine nahtlose Arbeit mit lokalen Dateien. Läuft das Werkzeug dagegen auf einem entfernten Server, sei es als Service oder in der Cloud, können Daten zwar von einem lokalen System eingelesen werden, alle Änderungen werden aber in der Anwendung gespeichert. Will man sie dann wieder lokal auf dem Dateisystem ablegen, müssen die Datenbankbestände explizit exportiert werden. Freilich betrifft die Vorgehensweise nur die lokale Speicherung der Daten und hat keinen Einfluss auf die Speicherung auf einem entfernten Server. Hier werden die Daten sofort synchronisiert und müssen weder manuell abgeglichen noch exportiert werden. Als Anbieter kommt dabei entweder ein eigener DAV-Server oder ein Dienstleister wie Dropbox, GoogleDrive oder OneDrive infrage. Je nach Dienstleister muss KeeWeb dann entsprechend konfiguriert werden. Bei WebDAV reicht es, die URL des Servers einzutragen und notfalls die Zugangsdaten zu ergänzen. Dropbox benötigt den API-Schlüssel und GoogleDrive oder OneDrive entsprechende Authentifizierungen.Der Einsatz
KeeWeb kann, wie schon das Original, zur Speicherung von Informationen genutzt werden. Die Datenbank der Anwendung kann sowohl als Passwortablage dienen als auch als Ort, in dem alle wichtigen Daten abgespeichert werden. Dank der Möglichkeit, Einträge auch um Anhänge zu ergänzen, lassen sich auch Dokumente in die Datenstruktur einbinden. Wird die Anwendung zum ersten Mal aufgerufen, ist es notwendig, entweder eine bereits bestehende KeePass-Datenbank einzulesen oder eine neue zu erstellen. Bei einer neuen Datenbank kann unter „Einstellungen“ nicht nur der Name der Datenbank festgelegt werden, sondern auch ihr Speicherort, das Master-Passwort sowie beispielsweise der Backup-Ort.
Neue Datenbank wird angelegt.
Die Benutzung der Anwendung gestaltet sich intuitiv. Neben bereits vordefinierten Feldern, wie beispielsweise „Passwort“ oder „Benutzer“ können auch selbst erstellte Felder generiert werden. Dazu reicht es, auf das Feld neben „mehr“ zu klicken und einen neuen Wert einzugeben. Ein weiterer Klick auf den Feldnamen „Neues Feld“ ermöglicht dann die Umbenennung des Feldnamens. So ist es beispielsweise möglich, Templates für verschiedene Bereiche zu erstellen, die später nur noch mit Daten gefüllt werden müssen.
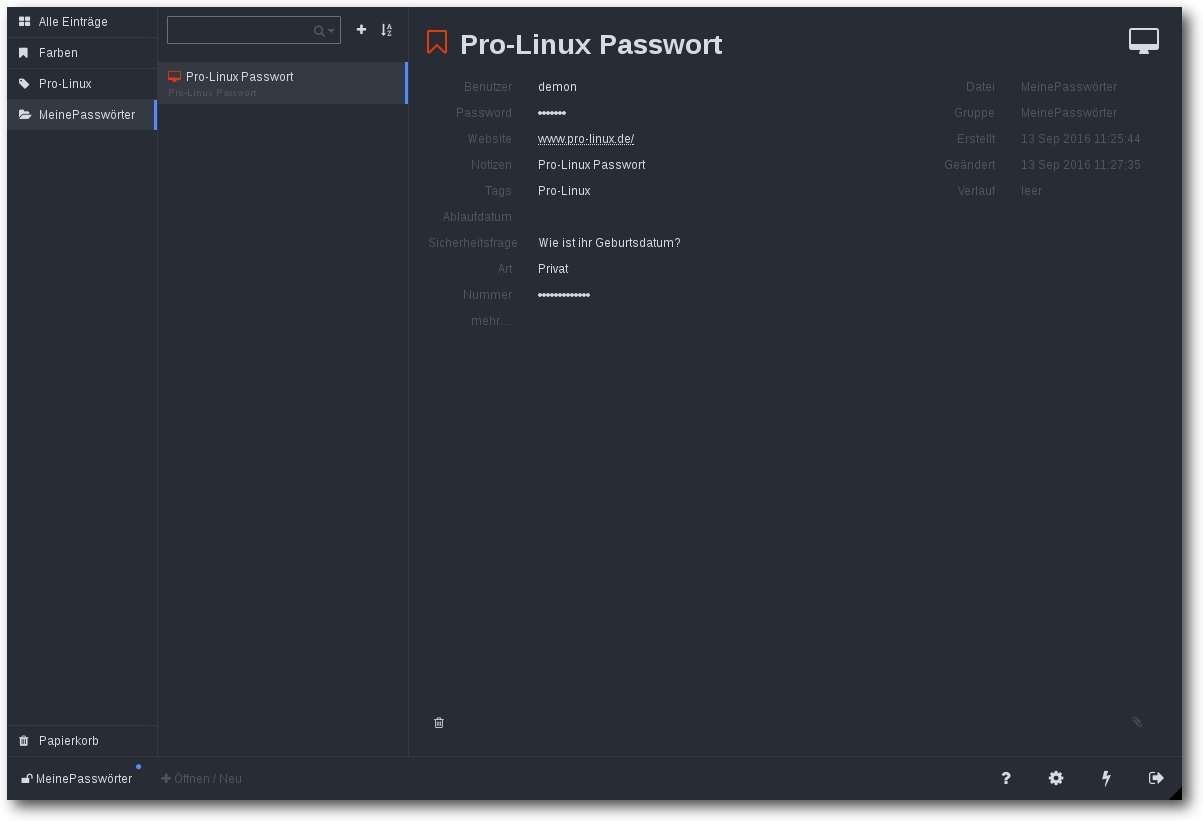
Einstellungen einer Datenbank.
Als Typen unterstützt die Anwendung eine sichtbare oder eine unsichtbare Anzeige der Daten. Erst bei einem Klick auf das mittels Sternen unkenntlich gemachte Feld wird der Inhalt dargestellt. Alternativ können Nutzer auf den Feldnamen klicken, was dazu führt, dass der Inhalt des Feldes in die Zwischenablage kopiert wird – eine durchaus nützliche Funktion, um beispielsweise schnell Benutzernamen oder Passwörter zu kopieren, ohne sie zuvor aufdecken zu müssen. Gespeicherte Einträge können gruppiert, mit Tags versehen oder farblich markiert werden. Zudem lassen sich direkt in der Anwendung parallel auch mehrere Datenbanken öffnen, was eine noch flexiblere Ablage der Daten ermöglicht. Jede der Datenbanken kann nämlich auf einem anderen Ort liegen und mittels eines separaten Passworts abgesichert sein.
Ablage eines Passworts.
Fazit
KeeWeb ist eine interessante Anwendung, die das Speichern von Daten in einem Format ermöglicht, das durch eine Vielzahl von Anwendungen unterstützt wird. So lassen sich mühelos zuvor in dem Werkzeug gespeicherte Daten zwischen diversen Systemen transferieren, bearbeiten und wieder einlesen. Die darin gespeicherten Daten können sowohl Passwörter als auch vertrauliche Daten oder Dokumente sein.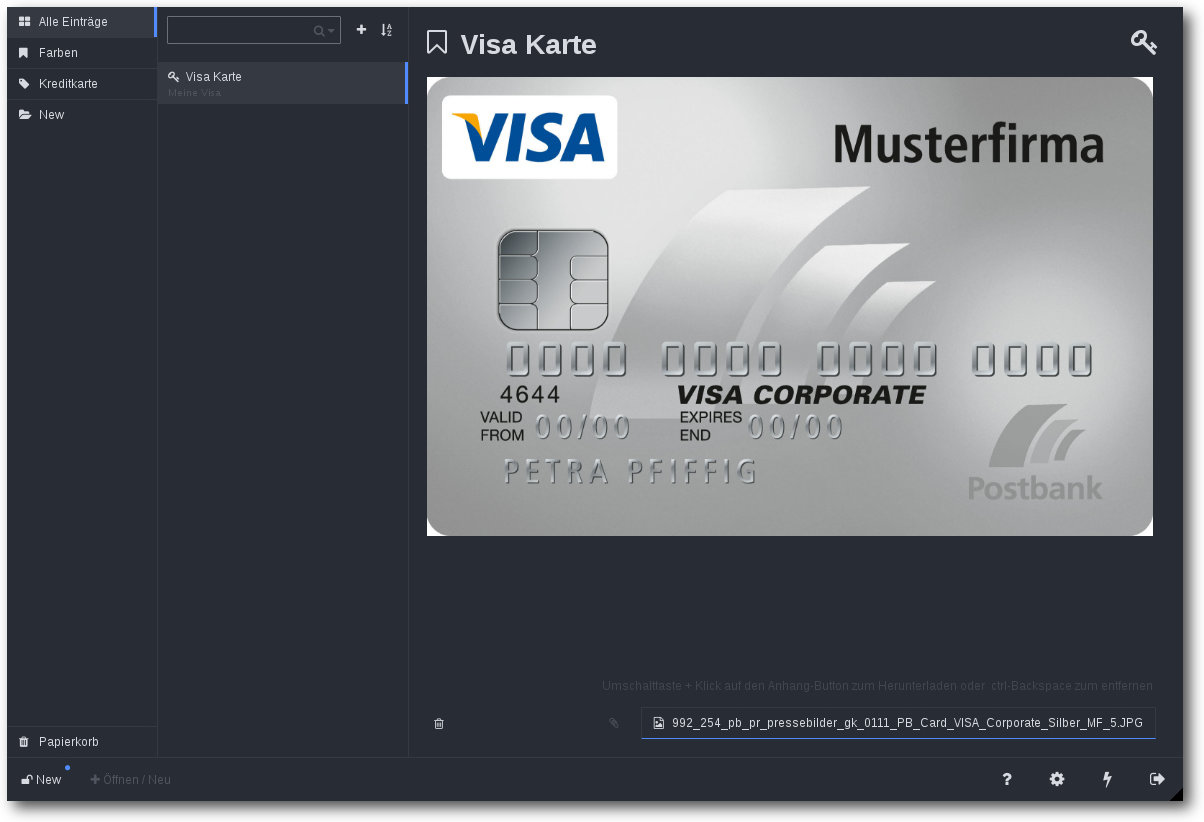
Einfache Anzeige von Daten.
Die Oberfläche des Tools ist durchdacht und klar strukturiert. Die Bearbeitung der Daten geht schnell von der Hand, und Funktionen wie das verdeckte Kopieren von Daten will man bereits nach wenigen Einsätzen nicht mehr missen. Doch auch die unaufgeregte und strukturierte Anzeige der Daten überzeugt. Störend ist dagegen, dass KeeWeb durchaus noch wichtige Funktionen, wie beispielsweise den Druck oder das Teilen, missen lässt. Zudem ließ in unseren Tests die Stabilität der WebDAV-Verbindung noch zu wünschen übrig. Wie schnell die Entwicklung voranschreitet, konnte man allerdings bei diesem Fehler sehen. Denn noch während der Text verfasst wurde, hat der Autor den Fehler korrigiert. Links
[1] http://www.pro-linux.de/artikel/2/1847/keeweb-passwörter-sicher-speichern.html
[2] http://keepass.info/
[3] https://www.keepassx.org/
[4] http://raymontag.github.io/keepassc/
Autoreninformation |
| Mirko Lindner (Webseite) befasst sich seit 1990 mit Unix. Seit 1998 ist er aktiv in die Entwicklung des Kernels eingebunden. Daneben ist er einer der Betreiber von Pro-Linux.de. |
Beitrag teilen Beitrag kommentieren
Zum Inhaltsverzeichnis
Test: Life is Strange – Emotionale Zeitreise
von David Schroff Life is Strange [1] besteht aus insgesamt fünf Episoden, wovon die erste kostenlos spielbar ist. Der Frage, für wen es sich lohnt, die kostenpflichtigen Episoden 2-5 dazu zu kaufen, wird in diesem Test nachgegangen. Redaktioneller Hinweis: Der Artikel „Test: Life is Strange – Emotionale Zeitreise“ erschien zuvor auf games4linux.de [2]. Die Zeit der Jugend prägt einen jeden Menschen auf seine Art. Gemeinsam mit Freunden werden spaßige Dinge erlebt, traurige und verrückte Dinge überstanden, es werden Freundschaften aufgekündigt, nur um sie Tage später wieder zu schließen. Die Schule mit den unterschiedlichsten Mitschülern ist ein anstrengender Ort und nicht selten möchte man einigen Gleichaltrigen einen Stempel mit den Worten „Tussi“, „Playboy“ oder „Milliardärs-Sohn“ auf die Stirn klatschen. In so einer typischen Welt lebt Maxine „Max“ Caulfield, die vom Spieler übernommene Protagonistin. Doch der Schein einer vermeintlich normalen Jugend trügt, das stellt sich gleich zu Beginn der ersten Episode heraus: Durch einen tragischen Vorfall mit ihrer Freundin Cloe muss Max erkennen, dass sie die Zeit zurückdrehen kann. Auf einen Schlag ist nichts mehr so, wie es war. Besonders der Umstand, dass die Umwelt von Max auf ihre Zeitreisen reagiert, lässt im Spielverlauf ein Feuerwerk an Emotionen hochgehen, welches kaum einen Spieler kalt lässt. Alle Episoden zusammen veranschlagen ungefähr 13 Spielstunden. Die Linux-Fassung wurde von Feral Interactive [3] im Juli 2016 veröffentlicht.Geschichte
Die emotionale Story von „Life is Strange“ bildet den Kern des Spiels. Annähernd alle Entscheidungen von Maxine verändern die Beziehungen zu den betroffenen Menschen. Allesamt Mitmenschen, zu denen Max jeweils eine besondere Beziehung hat: Die einen mag sie, die anderen mag sie nicht. Wie sie diese Beziehungen weiterhin führt, darf der Spieler entscheiden. Den roten Faden stellt die Freundschaft zu Cloe und gleichzeitig die mysteriösen Geschehnisse dar. Das Internat „Blackwell Academy“ umgeben viele Fragen, die einer Antwort bedürfen: Wieso besitzt der reiche Schnösel eine Pistole? Weshalb verfolgt der Stiefvater von Cloe, seinerseits angestellt für die Security am Internat, die introvertierte Mitschülerin Kate Marsh? Und überhaupt: Wo zum Kuckuck steckt das seit Monaten vermisste Mädchen Rachel Amber? In dieser Kleinstadt gehen unbestritten merkwürdige Dinge vor.
So einiges an der „Blackwell Academy“ läuft falsch. Was geht hier vor?
Die Tatsache, dass Max die Zeit zurückdrehen kann, inszeniert das Spiel mit aufrichtiger Leidenschaft: Cloe möchte einen Beweis dafür und so sagt Max Cloe kurzerhand die Zukunft voraus. Hierauf flippt Cloe fast völlig aus: „Hey Max, ist das geil! Wir können die ganze Welt verändern!“, kreischt sie vor Freude. „Los komm, lass uns raus gehen und unmögliche Dinge anstellen!“ Als Spieler huscht einem unweigerlich ein breites Grinsen über das Gesicht. Ja, das ist cool!

Viele Entscheidungen dürfen direkt in den Zwischensequenzen getroffen werden. Das kommt dem flüssigen Spielgefühl zugute.
An vielen Stellen konfrontiert uns das Story-Adventure mit ganz alltäglichen Problemen, und immer wieder hilft uns eine kurze Zeitreise zurück in die Vergangenheit, um die vermeintlich beste Lösung zu finden. „Life is Strange“ schafft es über alle fünf Episoden hinweg, sehr viele Gefühlswallungen an den Spieler zu vermitteln. Die Geschichte zwischen Max und Cloe nimmt an Fahrt auf, es passiert ununterbrochen etwas Trauriges, etwas Schönes, Nachdenkliches oder Verrücktes – und der Spieler ist jedes Mal mitten drin. Das Ende von Episode 3 stellt einen ganz besonderen Höhepunkt dar, der mit den Worten „Oh mein Gott!“ vielleicht schon jetzt, noch vor dem Show-down in Episode 5, zu ein paar Tränen führt. Spätestens zu Beginn von Akt 4 drängt sich die Frage auf: Was, wenn jede neue Entscheidung, die man trifft, alles nur noch schlimmer macht, obwohl man eigentlich nur Gutes tun möchte?
Gameplay
Abseits der Zeitreise und den vielen Dialogen zählt auch das Entdecken, ein bisschen wie ein Detektivspiel, zur Hauptaufgabe von Max. Immer dort, wo die Geschichte weitergeht, darf Maxine die Umgebung erkunden und kommt dank ihrer Fähigkeit an Gegenstände oder Informationen heran, die sonst unerreichbar gewesen wären. Schwer wird das Spiel dabei nie. Vereinzelt wirkt die Sucherei langatmig, wenn man einen dringend benötigten Gegenstand nicht sofort findet, die fortlaufende Geschichte entschädigt dann aber rasch wieder.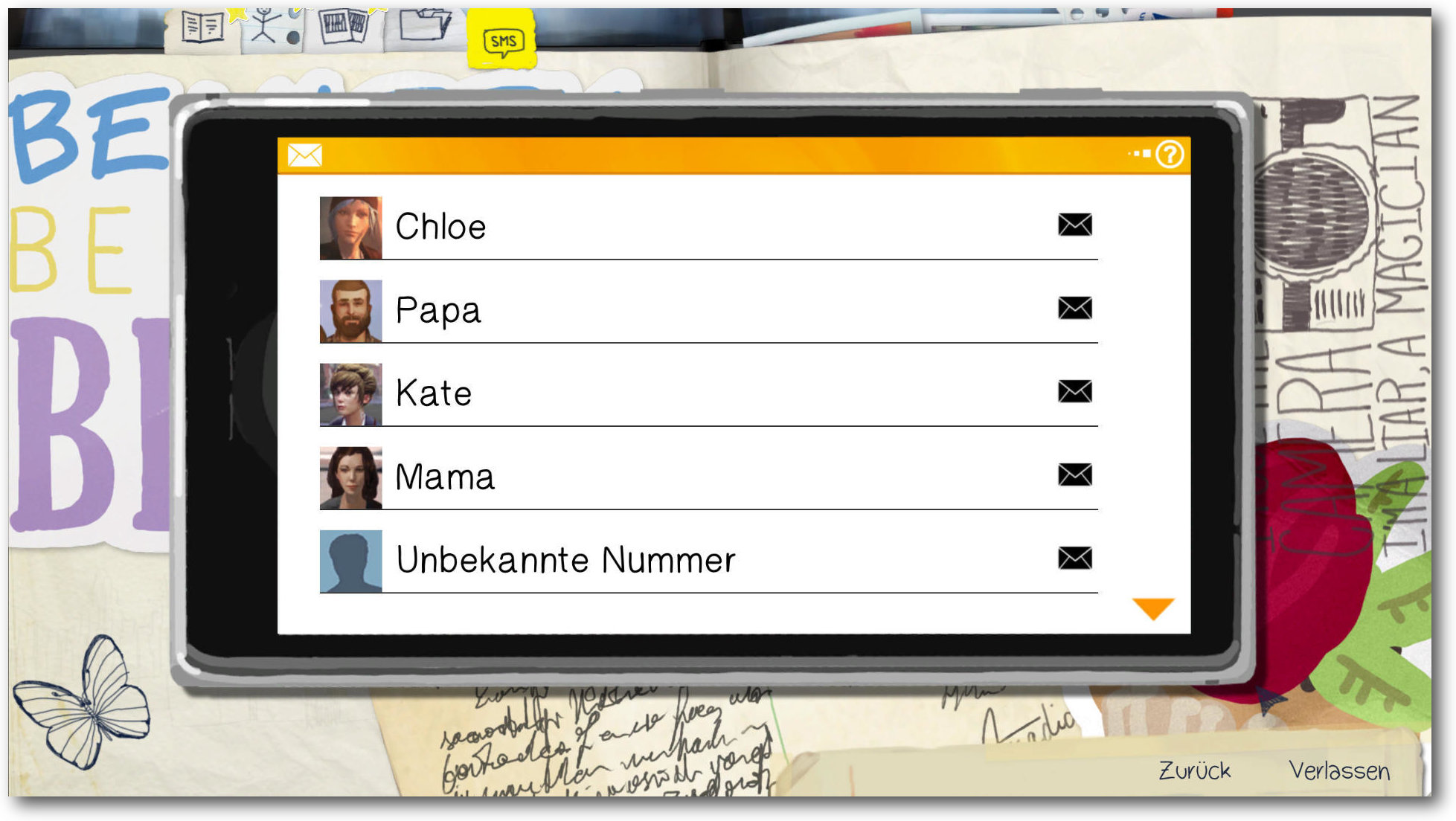
Max erhält auf ihr Smartphone immer wieder SMS von Freunden wie Feinden. Das hängt mit den getroffenen Entscheidungen zusammen.
Als schlecht zu bezeichnen bleibt lediglich ein Abschnitt im letzten, fünften Akt in Erinnerung: Während „Life is Strange“ seinem Ende entgegenrennt und das Ziel zum Greifen nahe ist, muss der Spieler unverhofft eine nervige Schleich-Passage durchlaufen. Dieser Abschnitt möchte zwar das Geschehene aufarbeiten, nervt dabei aber nur. Das ist schade und fühlt sich an wie ein versehentlicher Klecks in dem sonst passenden Gesamtbild. Am Ende des Spiels wird man erkennen müssen, dass die Entscheidungen zwar innerhalb der Episoden einen starken Einfluss haben, aber nicht auf das effektive Spielende. Davon gibt es durchaus unterschiedliche und als Spieler steht man unweigerlich vor der Entscheidung, das Ende zu wählen, das für einem selbst das richtige Ende ist. Doch was ist in diesem Spiel schon richtig, und was falsch?
Grafik
„Life is Strange“ basiert auf einer verbesserten Unreal-3-Engine. Die Lichtstimmung überzeugt, wenngleich die Details der Welt, der Umgebung und aller Charakteren etwas mau sind. Doch für diese Art von Story-Spiel passt der Grafikstil und wirkt nur in einem Punkt störend: der Mimik.
Die Grafikeinstellungen lassen rudimentäre Änderungen zu.
Leider werde alle animierten Gesichter den tollen Sprechern nicht gerecht. Am deutlichsten fällt das während des Show-downs in Episode 5 auf. Während die englischen Sprecher einen fantastischen Job abliefern, lassen sich die Gefühle nur schlecht aus den Gesichtern der Charaktere ablesen. Hier hätte der Entwickler DONTNOD Entertainment mehr Zeit investieren sollen. Als Mindestvoraussetzung wird eine Nvidia GTX 640 bzw. Radeon R9 270 angegeben. Für ein ruckelfreies Vergnügen sollte dennoch mindestens eine GTX 760 verbaut sein. Bei AMD-Grafikkarten gibt es Probleme, das Spiel unter SteamOS ans Laufen zu bekommen. Für den Linux-Desktop gibt der Entwickler einen Mesa 11.2-Treiber als Mindestvoraussetzung an, versäumt es aber, die empfohlene AMD-Grafikkarte anzugeben. Das Spiel wurde in 1920×1080 auf einem Gaming-Laptop mit einer Nvidia 960M getestet. Das entspricht in etwa einer Desktop-Grafikkarte im Leistungsbereich einer Nvidia 7xx GTX. Ruckler sind keine aufgetreten.
Sound
Dank der exzellenten Synchronsprecher ist die flache Mimik zu verschmerzen. Allgemein erscheint die Vertonung in allen Punkten gelungen, alle Charaktere haben eine perfekte Stimme erhalten. Einen weiterer Kniff für emotionale Höhenflüge beinhaltet die Musik, die an gewissen Stellen geschickt eingespielt wird. Wenn Max zum Beispiel in den Bus steigt und sich vom Stress des Alltags lösen möchte, steckt sie sich Kopfhörer ins Ohr – die Umgebung wird leiser, die Musik umgibt den Spieler wie ein warmes Tuch. Und zwar so lange, bis der Spieler eine Taste drückt.Fazit
„Life is Strange“ richtet sich an Menschen, die Gefühle zulassen und nicht blockieren. Wen Entscheidungen und deren (traurige) Konsequenzen in Spielen generell kalt lassen, wird es weniger genießen können. Lässt man hingegen dem Spiel die Freiheit sich zu entfalten und saugt die Spielwelt in sich auf, wartet als Belohnung ein emotionales Feuerwerk. Ganz klar eine Empfehlung für Story-Enthusiasten! Ja, Max's Freundin Cloe ähnelt dem Typ, der gemeinhin als „Emo“ bezeichnet wird, aber genau das bringt das Spiel fantastisch zur Geltung: Die Jugend, die darin erlebten Undinge der Kindheit und eine unzertrennliche Freundschaft zwischen zwei Mädchen. Links[1] http://www.lifeisstrange.com/
[2] https://games4linux.de/test-life-is-strange-emotionale-zeitreise/
[3] https://www.feralinteractive.com/
Autoreninformation |
| David Schroff (Webseite) spielt seit 2012 unter Linux, aktuell mit Linux Mint 18. Beruflich ist er im Bereich Middleware auf Linux-Servern unterwegs. |
Beitrag teilen Beitrag kommentieren
Zum Inhaltsverzeichnis
Spieltipp: Don't take it personally, babe, it just ain't your story
von Jakob Moser Die Visual Novel [1] „Don't take it personally, babe, it just ain't your story“ [2] spielt im Jahr 2027 und wurde von Spieleentwicklerin Christine Love [3] geschaffen. Der Spieler schlüpft in die Rolle des Highschool-Lehrers John Rook, der Zugriff auf alle Nachrichten hat, die die Schüler sich untereinander über das soziale Netzwerk AmieConnect schicken.
Das Hauptmenü.
So erfährt man von den Leben von sieben Schülern, ihren Beziehungen und ihrer Entwicklung. Außerdem thematisiert das Spiel die Bedeutung von Privatsphäre, die bei den Schülern in der Zukunft einen anderen Stellenwert hat als heute. Die Geschichte spielt die meiste Zeit in einer privaten Highschool in Ontario und ist in sieben Kapitel geteilt, eines für jeden der Protagonisten. Das Spielprinzip ist klassisch für Visual Novels: Als Spieler klickt man sich durch Gespräche und Gedanken, gelegentlich muss man sich zwischen verschiedenen möglichen Aktionen entscheiden.

Ein innerer Monolog von John Rook.
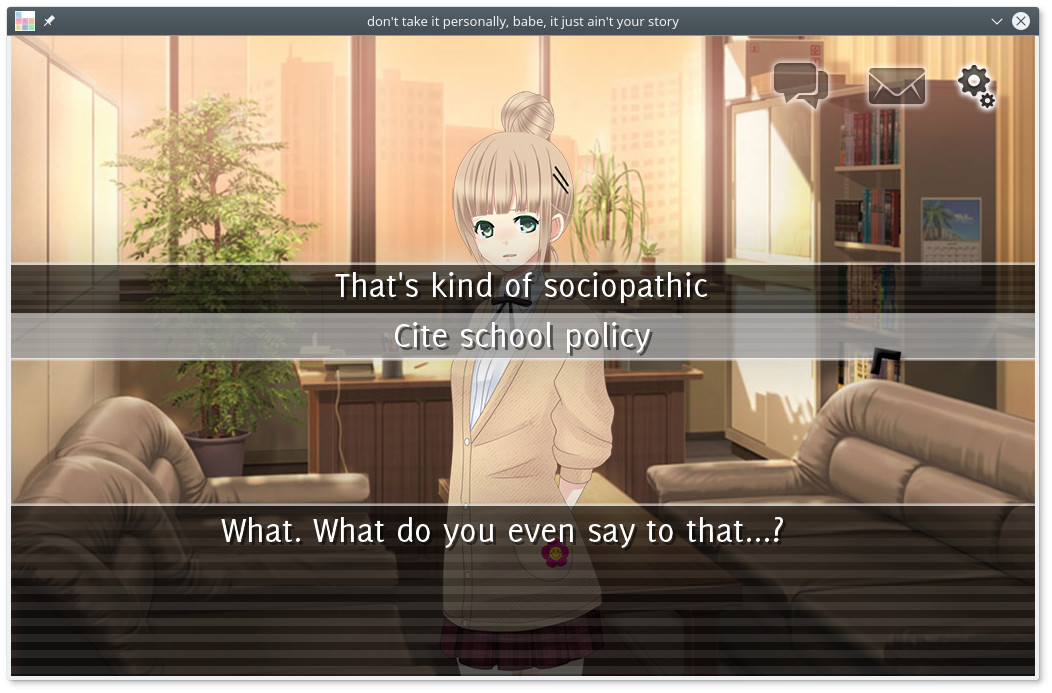
Hier hat man die Qual der Wahl.
Die Besonderheit des Spiels, dass man als Spieler die Nachrichten der Schüler mitlesen kann, wurde über ein kleines Nachrichtensymbol rechts oben umgesetzt. Leuchtet es auf, kann man durch einen Klick die Nachrichten lesen, die sich die Schüler gerade schreiben. Über das Briefsymbol kann man die eigenen Mails lesen (diese Funktion kommt im Spiel aber nur wenige Male zum Einsatz) und über das Einstellungsmenü kann man Spielstände laden, speichern und das Spiel beenden.

Sie haben neue Nachrichten.
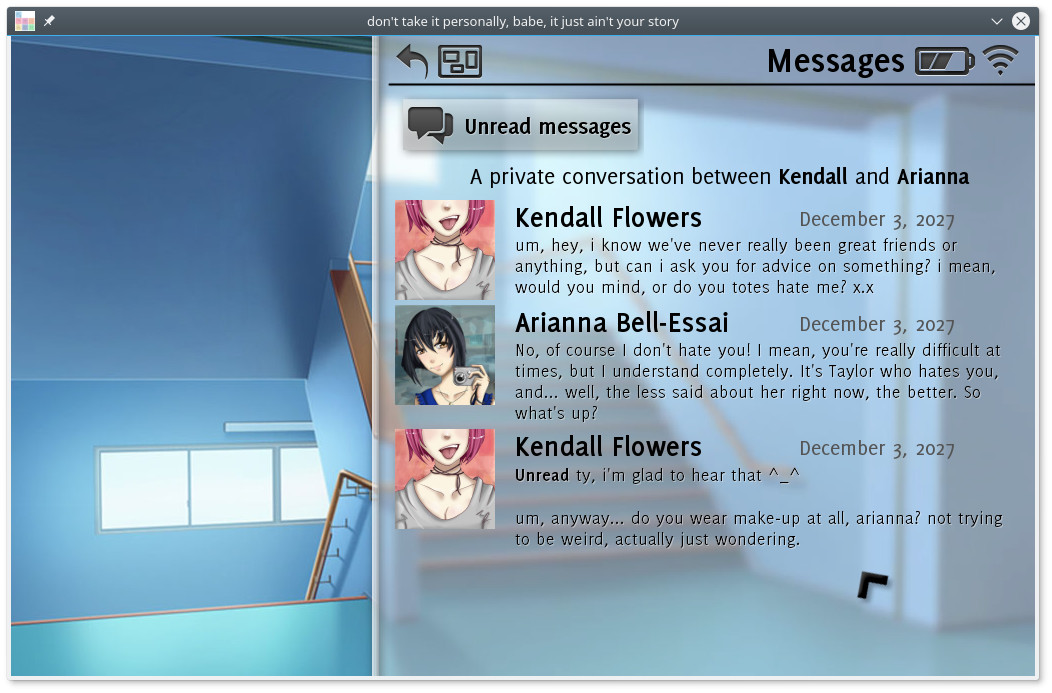
Ein privates Gespräch.
In jedem Kapitel lernt man einen der Schüler besser kennen: Im ersten Kapitel die schüchterne Arianna, im zweiten Kapitel den schweigsamen Riesen Nolan und im dritten Kapitel das notorisch deprimierte Mädchen Isabella. Im vierten Kapitel erfährt man mehr über die brave, fleißige Charlotte, im fünften über die wegen ihrer Art unbeliebten Taylor. Kapitel sechs handelt von der aufgedrehten Kendall und im siebten Kapitel erfährt man mehr über den Jungen Akira. Man erlebt mit, wie neue Beziehungen und Freundschaften entstehen (manchmal muss man sogar dabei helfen) und sieht, wie alte Beziehungen sich auflösen oder Konflikte beigelegt werden. Auch in den Lehrer, der seine ganz persönlichen Probleme hat, kann man sich im Laufe des Spiels immer besser hineinversetzen.
Installation
Das Spiel wurde mithilfe der auf Python basierenden Visual-Novel-Engine Ren'Py [4] erstellt und lässt sich von der Homepage des Spiels [2] herunterladen. Das Paket sollte alle benötigten Bibliotheken (Python [5] und Pygame [6]) enthalten – wenn wider Erwarten etwas nicht funktioniert, kann man Python 2 und Pygame aber natürlich auch über den Paketmanager installieren. Das Spiel kann über die Datei don't take it personally, babe.sh gestartet werden.Fazit
Wer gerne in Beziehungskomplexe eintaucht und kein Problem damit hat, lange Dialoge zu lesen, der sollte mit diesem Spiel voll auf seine Kosten kommen. Die verschiedenen Charaktere sind interessant und tiefgründig gestaltet, die Umgebungen sind hübsch und die Handlung ist fesselnd – ein Muss für jeden Visual-Novel-Fan. Für jeden, der mit diesem Spiel auf den Geschmack gekommen ist, steht auf der Ren'Py-Homepage eine Liste an Visual Novels [7], die mit dieser Engine erstellt wurden, bereit. Links[1] https://de.wikipedia.org/wiki/Japanisches_Adventure
[2] http://scoutshonour.com/donttakeitpersonallybabeitjustaintyourstory/
[3] http://loveconquersallgam.es/
[4] http://renpy.org/
[5] https://www.python.org/
[6] http://www.pygame.org/hifi.html
[7] http://games.renpy.org/
Autoreninformation |
| Jakob Moser nutzt seit längerer Zeit Linux, im Moment Arch Linux. Auf das Spiel und seinen ideellen Vorgänger „digital“ ist er über das ubuntuusers-Wiki gestoßen. |
Beitrag teilen Beitrag kommentieren
Zum Inhaltsverzeichnis
Test: The Curious Expedition – ein Roguelike-Abenteuer für Forscher und Entdecker
von Dennis Weller Auf der Suche nach Abenteuern, Schätzen und Ruhm kann man sich im rundenbasierten Roguelike „The Curious Expedition“ [1] auf den Weg machen und die goldenen Pyramide in sechs Expeditionen finden. Doch das ist leichter gesagt als getan, wie der Artikel zeigt. Redaktioneller Hinweis: Der Artikel „Test: The Curious Expedition“ erschien erstmals bei Games4Linux [2]. Redaktioneller Hinweis: Da das Entwickler-Studio Maschinen-Mensch die Bilder nicht unter einer freien Creative-Commons-Lizenz freigeben wollte, kommt der Artikel ohne Bilder aus. In „The Curious Expedition“ begibt man sich mit einer von 17 bekannten Persönlichkeiten des 19. Jahrhunderts auf Forschungsreise. Die Mitglieder des Clubs der Entdecker schließen eine Wette darüber ab, wer in sechs Expeditionen die meisten Schätze bergen und dadurch Ruhm erlangen kann. Der ist wichtig, um zu gewinnen, denn wer nach den sechs Reisen am meisten Ruhm hat, gewinnt. Doch gilt es zunächst, diese überhaupt erfolgreich abzuschließen. Dabei findet man allerhand Ruinen, verlassene Lager, Schreine und selbst Dörfer von indigenen Völkern. Auch wilden Tieren und anderen Gegnern muss man sich stellen. Darunter finden sich Krokodile, Hyänen und Tiger. Selbst gigantische Skorpione, Mumien, Riesenspinnen und sogar Dinosaurier stellen sich den Forschern von Zeit zu Zeit in den Weg.Der Club der Forscher und Entdecker
Zuallererst wählt man seinen Charakter aus. Ganz am Anfang steht lediglich Charles Darwin zu Auswahl. Im Laufe des Spiels schaltet man durch das Erreichen von bestimmten Voraussetzungen dann nach und nach die anderen 16 Charaktere frei. Zu Darwin gesellen sich noch Marie Curie, Richard Francis Burton, Frederick Courtney Selous, Mary Kingsley, Johan Huizinga, Marcus Garvey, Aleister Crowley, Nikola Tesla, Amelia Earhart, Alexandra David-Neel, Dion Fortune, Freya Stark, Isabella Bird, Harriet Tubman, Ada Lovelace und H.P. Lovecraft. Alle diese Personen haben verschiedene Besonderheiten. Daher sollte man sich gut überlegen, wen man wählt, da dies im Wesentlichen den Spielstil beeinflussen kann. So ist Mary Kingsley Pazifistin und kann daher im Kampf keine Waffen nutzen. Frederick Selous hingegen startet gleich mit einem Jagdgewehr und hat zudem den Bonus des Dschungelforschers, was ihn und seine Begleiter weniger geistige Gesundheit kostet, wenn sie sich durch dichte Wälder begeben. Die Spezialität von Richard Burton sind Sprachen. Daher fällt es ihm nicht schwer, sich mit den Bewohnern der bereisten Orte zu verständigen und er bekommt, zusammen mit seinen Begleitern, einen kostenlosen Platz zum Schlafen angeboten. Oder H.P. Lovecraft. Er ist der einzige Charakter, der das berüchtigte Necronomicon sicher nutzen kann, ohne zu schnell verrückt zu werden. Ihn kostet die Anwendung nur 35 statt 70 der geistigen Gesundheit. Diese benötigt man für die Fortbewegung im Spiel. Dabei kostet jeder Zug einen festgelegten Grundwert, zu dem weitere Kosten für die Entfernung und die Art der überquerten Felder kommen. Daher sollte man sich jeden Zug gut überlegen und, wegen des Grundwerts, möglichst weite Distanzen pro Zug hinter sich bringen, um seinen Verstand zu schonen. Das Durchqueren von Wäldern oder Sümpfen kostet dabei mehr geistige Gesundheit als wenn man über Wiesen und Felder läuft.Die Mächte des Wahnsinns
Sinkt der Wert der geistigen Gesundheit auf Null, so fangen die Mitglieder der Gruppe an, verrückt zu werden. Sie beginnen, mit anderen zu streiten, reden mit Personen, die nicht da sind oder nehmen sich aus Verzweiflung das Leben. Es kann aber auch passieren, dass sie zu Kannibalen werden oder euren Packesel schlachten wollen. Auch der vom Spieler gewählte Charakter ist davor nicht gefeit. Dem entgegenwirken kann man nur, wenn man dafür sorgt, dass die geistige Gesundheit immer wieder aufgefüllt wird. Dazu kann man Schokolade naschen oder, hat man einen Koch bei sich, Fleisch von besiegten Tieren essen. Auch Alkohol sorgt für ein wenig mehr Seelenheil in „The Curious Expedition“, bringt aber auch die Gefahr mit sich, dass Begleiter zu Alkoholikern werden. Sollte man sich in der Nähe eines Dorfes befinden, kann man dort nächtigen und ein paar Zugpunkte zurückzugewinnen. Man kann auch jederzeit zum Schiff zurückkehren und dort schlafen, um den selben Effekt zu erzielen. Außerdem gibt es noch religiöse Missionen, bei denen man gegen einen nicht unbeträchtlichen Gegenwert übernachten darf.Geld allein macht auch nicht glücklich
Die Währung in „The Curious Expedition“ setzt sich aus Geld und aus Gegenständen zusammen. Während man mit dem Geld vor jeder Reise Ausrüstung kaufen oder die Kapazität seiner Lasttiere aufbessern kann, nutzt man während der Expedition die Gegenstände, um zu handeln. Jedes Objekt hat einen Wert (der auch mal Null sein kann) und kann als Zahlungsmittel in Dörfern, Missionen und bei Händlern eingesetzt werden. Weitere Gegenstände findet man unter anderem beim Erkunden von Höhlen, Schreinen und Götzenstatuen. Allerdings sollte man sich bewusst sein, dass die Einheimischen nicht gerade erfreut sind, sollte man sich ihre Opfergaben zu Eigen machen oder heilige Kultstätten entweihen. Zudem kann es sein, dass man durch seinen gemeinen Diebstahl in Tempeln nicht nur die ansässigen Kulturen verärgert, sondern sogar riesige Katastrophen wie Brände, Überschwemmungen oder Dürre auslöst. Vielleicht könnte man die Schätze à la Indiana Jones einfach austauschen, in der Hoffnung, das selbe Gewicht mit seinen hoffentlich wertlosen Gegenständen auszugleichen? In jedem Fall muss man damit rechnen, dass man bei seinen Beutezügen den Zorn der Bewohner auf sich zieht, was nicht unbedingt erwünscht ist.Bitte recht freundlich
Die Stimmung der Einheimischen ist wichtig, damit sie dem Spieler beim Besuch ihres Dorfes wohlgesonnen sind und sich nicht gegen ihn stellen. Die Gefühlslage lässt sich übrigens auch durch Spenden heben, indem man Gegenstände beim Handel anbietet, ohne eine Gegenleistung zu fordern oder indem man Güter mit deutlich mehr Wert als dem der Handelsobjekte der Einwohner abgibt. Nur dann ist es auch möglich, Bewohner zu rekrutieren, damit sie sich der Gruppe anschließen. Meist haben diese aber recht schnell Heimweh und werden den Spieler nach der Expedition wieder verlassen, um in ihr Dorf zurückzukehren. Mit etwas Glück überreden die Würfel den neuen Begleiter aber mitzukommen, um für weitere Reisen zur Verfügung zu stehen. Einfacher zu handhaben sind da Tiere wie Esel oder Büffel. Diese bekommen kein Heimweh und können aufgebessert werden, um mehr Gegenstände zu tragen. Bei Kämpfen stehen sie jedoch nicht zur Seite, sollten diese stattfinden. Dagegen können Hunde, sollten sich diese in der Gruppe befinden, kräftig austeilen.Das Kampfsystem
Kämpfe werden in klassischer Pen-&-Paper-Rollenspiel-Manier mit Würfeln ausgetragen. Daher ist auch die Wahl der Gefährten wichtig, damit man die Würfel der Hauptperson dem eigenen Spielstil nach möglichst gewinnbringend mit anderen Würfelarten ergänzt. So gibt es Würfel für den Angriff, für die Verteidigung, zur Unterstützung und Magie. Dazu kommen noch spezielle Würfel für besondere Waffen, Patronen oder Tiere. Würfe lassen sich kombinieren, um noch stärkere Angriffe auszuführen oder um sich besser zu schützen. Geht man aus einem Kampf als Sieger hervor, so bekommt man meistens Felle oder Zähne der tierischen Gegner, die entweder getauscht werden können oder sich in Geld oder Ruhm umwandeln lassen. Auch Fleisch bekommt man ab und zu, welches von einem Koch in eine essbare Mahlzeit umgewandelt werden kann. Je nach Level des Kochs bekommt man mehr geistige Gesundheit zurück. Es ist auch möglich, vor Kämpfen zu fliehen. Dabei kann es passieren, dass man Gegenstände oder gleich ganze Mitstreiter verliert. Es bleibt über das gesamte Spiel also, nicht nur in Kämpfen, ein ständiges Abwägen der gegebenen Situationen, um hoffentlich die richtige Entscheidung zu treffen. Letztlich geht es nur ums Überleben, denn das ist die Voraussetzung, um die nächste Reise in Angriff nehmen zu können.Auf ein Neues
Bei „The Curious Expedition“ ist, wie es sich für einen Vertreter der Roguelikes gehört, das Spiel zu Ende, sobald man stirbt. Das kann manchmal schneller passieren als einem lieb ist. Auch wenn ein Durchgang des Spiels nur etwa zwei bis drei Stunden an Zeit beansprucht, so bietet es doch einiges an Wiederspielwert, zumal es den wenigsten gelingen wird, gleich beim ersten Mal ans Ziel zu kommen. Es wird nicht nur bei einem Neustart bleiben. Auch die Rollenspiel-Elemente machen den Titel sehr interessant. Neben den rundenbasierten Würfelkämpfen gibt es auch Erfahrungspunkte. Entdeckt man auf einer Karte drei neue Gebiete, bekommt man einen Punkt, welchen man auf seine Gefährten verteilen kann, um deren Eigenschaften zu verbessern. Man sollte aber auch darauf achten, dass sie einem treu bleiben, damit diese nicht umsonst vergeben wurden. Es kann nämlich vorkommen, dass man von Begleitern der Expedition verlassen wird, wenn zu viele Meinungsverschiedenheiten eintreten. Dass die Begleiter auch sterben können, ist nicht nur durch die Kämpfe, sondern auch durch Krankheiten oder Verletzungen ein weiteres Risiko. Vor jeder Reise bekommt man in der Regel auch einen Auftrag zugewiesen, den es zu erfüllen gilt. Schafft man das, so wird man dafür belohnt. Es ist aber kein Muss, den Auftrag anzunehmen, sollte dieser zu schwierig oder nicht sinnvoll erscheinen. Auch die verschiedenen Charaktere bereichern das Spiel auf ihre Art und verleihen jedem neuen Durchgang eine weitere Herausforderung. Zudem nehmen die wählbaren Figuren nicht nur durch ihre vom Spiel zugewiesenen Eigenschaften, sondern auch durch ihre Persönlichkeiten weiteren Einfluss auf das Geschehen. So kann es passieren, dass Lovecraft, welcher bekannterweise in seinen jüngeren Jahren nicht sehr offen für andere Kulturen war, einen Begleiter in einem Gespräch von seiner Sichtweise überzeugt und ihn dadurch zum Rassisten macht. Es sind gerade diese kleinen Details, diese besonderen Eigenschaften, für die sich die Entwickler ins Zeug gelegt haben, um jedem der 17 Forscher einen besonderen Charme zu verleihen. Dadurch bekommt das Spiel nochmal etwas mehr Würze und lässt den Spieler das eine oder andere Mal aufgrund der Geschehnisse schmunzeln, auch wenn diese nicht unbedingt zum Lachen sind.Abenteuer mit Wiederspielwert
Die verschiedenen Persönlichkeiten, die zur Auswahl stehen, bieten alleine schon genügend Variationen für viele unterschiedliche Herausforderungen. Dazu kommt noch das Ressourcenmanagement und die komplett zufallsgenerierten Welten, wodurch jeder Durchgang anders abläuft und es immer Neues zu entdecken gibt. Auch kann man sich lange Zeit mit den vielen unterschiedlichen Herangehensweisen auseinandersetzen und neue Ansätze ausprobieren. Oder man versucht, das Spiel ganz ohne Kämpfe zu bestehen oder es zu beenden, ohne Schätze zu rauben. Dadurch wird es natürlich sehr schwierig, sich die nächste Expedition zu finanzieren und sich nebenbei auch noch genug Ruhm zu erarbeiten, um als Sieger aus der Wette hervorzugehen. Kehrt man nämlich erfolgreich von einer Reise zurück, so muss man sich entscheiden, welche der gefundenen Schätze man behält, um sie auf die nächste Reise mitzunehmen, oder ob man sie verkauft, um mehr finanzielle Mittel für die Ausrüstung der Expedition zu haben. Man kann die Fundstücke aber auch an ein Museum spenden, um dafür Ruhm zu bekommen – und auf den kommt es letzten Endes an, damit man das Spiel gewinnen kann. Die beiden letztgenannten Möglichkeiten, das Spiel ohne Kämpfe oder ohne Schätze zu rauben zu beenden, sind nebenbei Voraussetzungen, um weitere Charaktere freizuschalten. Wem das jetzt alles etwas zu viel auf einmal ist, dem sei das offizielle Wiki zum Spiel empfohlen [3]. Allerdings steht dieses, wie auch das Spiel selbst, zum momentanen Zeitpunkt nur auf englisch zur Verfügung.Sprachbarriere
Sollte das Spiel erfolgreich genug sein, dass die Entwickler auch weiterhin genügen Ressourcen haben, um weiter an „The Curious Expedition“ zu arbeiten, so sollen gleich mehrere Übersetzungen folgen [4]. Da die Entwickler selbst aus Deutschland kommen, sollte eine deutsche ziemlich sicher sein. Auch über eine Möglichkeit, die Community einzubinden, wird momentan nachgedacht. „The Curious Expedition“ wurde von Maschinen-Mensch [5] entwickelt. Dieser Entwickler setzt sich momentan aus zwei ehemaligen Mitarbeitern des deutschen Studios Yager zusammen, welche dort unter anderem an „Spec Ops: The Line“ beteiligt waren. Maschinen-Mensch hat seinen Sitz, ebenso wie der frühere Arbeitgeber, in Berlin. „The Curious Expedition“ ist auf Steam, GOG und im Humble Store erhältlich. Den wirklich gelungenen und sehr passenden Soundtrack gibt es für 8,99 Euro auf Steam. Laut der Shop-Seite handelt es sich dabei allerdings um einen DLC, der das Spiel voraussetzt. Ein Glück, dass dieser auch auf Bandcamp angeboten wird [6].Endergebnis
„The Curious Expedition“ lädt zu einer abenteuerlichen Wette ein, bei der es nicht nur um Ruhm und Schätze geht, sondern auch ums bloße Überleben. Untermalt wird das Ganze von einem stimmungsvollen Soundtrack, der den Spieler bei seinen Reisen begleitet. Die vielen verschiedenen Charaktere bieten dabei mit ihren Eigenheiten und den sehr zu ihnen passenden möglichen Auswirkungen genug Anreize für viele unterhaltsame Spielstunden. Links[1] http://curious-expedition.com/
[2] https://games4linux.de/test-the-curious-expedition-ein-roguelike-abenteuer-fuer-forscher-und-entdecker/
[3] http://curious-expedition.wikia.com/wiki/Curious_Expedition_Wiki
[4] https://steamcommunity.com/app/358130/discussions/0/620713633864893543/#c617336568065249115
[5] http://maschinen-mensch.com/
[6] https://selbstserum.bandcamp.com/album/the-curious-expedition-original-soundtrack
Autoreninformation |
| Dennis Weller (Webseite) ist seit 2004 begeisterter Linux-Anhänger, ausgebildeter Mediengestalter und studiert nebenher Digitale Medien. Seine Begeisterung für Spiele startet mit einem Amiga 500 und einem Game Boy aus dem Jahre 1990. |
Beitrag teilen Beitrag kommentieren
Zum Inhaltsverzeichnis
Rezension: Scrum
von Sujeevan Vijayakumaran Das Buch „Scrum – Produkte zuverlässig und schnell entwickeln“ von Autor Boris Gloger [1] ist ein Buch über das Vorgehensmodell für Projekt- und Produktmanagement Scrum und ist mittlerweile in der fünften Auflage erschienen. Redaktioneller Hinweis: Wir danken Hanser für die Bereitstellung eines Rezensionsexemplares.Was steht drin?
Das Buch umfasst insgesamt 353 Seiten und unterteilt sich in 10 Kapitel. Zuerst beginnt das Buch mit den grundlegenden Informationen zu Scrum: Dort werden Fragen zu den Prinzipien, Geschichten und die Hintergründe erläutert. Im zweiten Kapitel folgt dann die Erläuterung der Rollen: Wer ist der Product Owner, was macht der Scrum-Master und welches sind die weiteren wichtigen Rollen und was machen diese? Die ersten beiden Kapitel geben zunächst einen Einstieg in die Thematik, die in den darauf folgenden Kapiteln weiter vertieft werden. So geht es im dritten Kapitel um das strategische Planen in Scrum, wo es um die Vision, das Product Backlog und das Schätzen geht. Das anschließende vierte Kapitel beschreibt dann, wie der Sprint mit den zuvor geplanten Tätigkeiten abläuft. Dabei geht es um den kompletten Sprint-Zyklus: Sprint Planning, Daily Scrum, Sprint Review und die Sprint-Retrospektive. Die übrigen Kapitel gehen weiter auf die weiteren nützlichen Themen ein. In Kapitel 5 geht es um das Reporting, wo verschiedene Charts vorgestellt werden, mitsamt Beispielen, Einsatzzwecken und Vor- und Nachteilen. Interessant ist auch das sechste Kapitel, wo es um die Skalierung von Scrum geht. Der Autor zeigt verschiedene Ansätze von Scrum Teams in verschiedenen Größen, Lagen und Strukturierungen und wie diese effizient arbeiten können. Das Buch schließt in den letzten drei der zehn Kapitel ab; im achten Kapitel geht es um Leadership, Emotion und Kreativität, gefolgt vom Management im neunten Kapitel. Das letzte Kapitel zeigt nochmals kurz an zwei Fallstudien, wie Firmen mit Scrum arbeiten.Wie liest es sich?
Das Buch wurde von Boris Gloger geschrieben. Laut der Autoreninformation auf dem Buchrücken ist er der bekannteste Scrum-Berater im deutschsprachigen Raum und hat namhafte Unternehmen beraten. Diese Kenntnisse und Erfahrungen, die der Autor in seiner täglichen Arbeit gesammelt hat, merkt man quasi auf jeder Seite des Buches. Der Autor beschreibt viele Dinge in seinem Buch äußerst ausführlich und sehr gut nachvollziehbar. Die Erläuterungen werden durch den Einsatz von Einschüben aufgelockert. In diesen Einschüben werden häufig Personen und Konversationen nachgespielt, welche die eine oder andere zuvor erklärte Eigenschaft von Scrum verdeutlichen soll. Diese Konversationen werden durch fiktive Personen in ihren Rollen – sei es mit oder ohne Scrum – dargestellt. Auch wenn diese eigentlich fiktiv sind, bilden sie wohl doch sehr häufig die Wirklichkeit ab. Die Beispiele dürfte wohl fast jeder Software-Entwickler nachvollziehen können, insbesondere wenn es um Funktionen und Hierarchien in Firmen, Geld, Strukturierung und die Planung von Projekten geht. Der Autor stellt im Vorwort klar, dass er unzufrieden ist, wie unproduktiv viele Firmen und Projekte arbeiten und möchte dies ändern. Und diese zahlreichen unproduktiven und ineffektiven Arbeitsweisen macht er in seinem Buch sehr gut deutlich.Kritik
Die jahrelange Erfahrung des Autors in diesem Business spiegelt sich sehr stark im Buch wieder. An vielen Stellen werden Fehler und Verbesserungsmöglichkeiten genau dann aufgezeigt, wenn man sich dies als Leser selbst fragt. Viele Edge-Cases – vor allem in den vorhandenen Strukturen von Firmen – werden abgedeckt. Die zahlreichen Einschübe mit den fiktiven Gesprächen bilden die zuvor beschriebenen Probleme sehr gut ab und es bleiben generell wenige Fragen offen. Vor allem die Projekt-Beispiele machen das Buch nicht trocken und langweilig, sondern regen auch zum Nachdenken an. Das Buch ist mit einem Preis von knapp 40€ wahrlich nicht billig, dürfte aber für viele Teams, die zu Scrum wechseln wollen, eine gute Investition sein, um das tägliche Arbeiten effektiver, zufriedener und produktiver zu gestalten – und das wohl für jeden Teilnehmer im Scrum-Prozess.Buchinformationen | |
| Titel | Scrum – Produkte zuverlässig und schnell entwickeln [1] |
| Autor | Boris Gloger |
| Verlag | Hanser, 2016 |
| Umfang | 353 Seiten |
| ISBN | 978-3446447233 |
| Preis | 39,99 € (Buch), 31,99 € (E-Book) |
Links
[1] http://www.hanser-fachbuch.de/buch/Scrum/9783446447233
Autoreninformation |
| Sujeevan Vijayakumaran (Webseite) arbeitet neben dem Studium als Software-Entwickler in einem Unternehmen, in dem Scrum eingesetzt wird. |
Beitrag teilen Beitrag kommentieren
Zum Inhaltsverzeichnis
Veranstaltungskalender
Messen | ||||
| Veranstaltung | Ort | Datum | Eintritt | Link |
| Ubucon Europe | Essen | 18.11.–20.11.2016 | – | http://ubucon.eu/ |
| BSides | Wien | 22.11.2016 | frei | http://bsidesvienna.at/ |
| LinuxDay | Dornbirn | 26.11.2016 | frei | http://linuxday.at/ |
| Chaos Communication Congress | Hamburg | 27.12.–30.12.2016 | 100 EUR | https://events.ccc.de/congress/2016 |
| Global Game Jam | Weltweit | 20.01.–22.01.2017 | frei | http://globalgamejam.org/ |
| FOSDEM | Brüssel | 04.02.–05.02.2017 | – | https://fosdem.org/ |
| Chemnitzer Linux-Tage | Chemnitz | 11.03.–12.03.2017 | – | http://chemnitzer.linux-tage.de/ |
| Easterhegg | Frankfurt/M. | 14.04.–17.04.2017 | – | https://easterhegg.eu/ |
Vorschau
freiesMagazin erscheint am ersten Sonntag eines Monats. Die Dezember-Ausgabe wird voraussichtlich am 4. Dezember u. a. mit folgenden Themen veröffentlicht:- Automatisierung mit Jenkins 2.0
- Gaming-Maus im Linux Test: Roccat Kova 2016
- Rezension: NODE.js - Professionell hochperformante Software entwickeln
Konventionen
An einigen Stellen benutzen wir Sonderzeichen mit einer bestimmten Bedeutung. Diese sind hier zusammengefasst:| $: | Shell-Prompt |
| #: | Prompt einer Root-Shell – Ubuntu-Nutzer können hier auch einfach in einer normalen Shell ein sudo vor die Befehle setzen. |
| ~: | Abkürzung für das eigene Benutzerverzeichnis /home/BENUTZERNAME |
Impressum ISSN 1867-7991
freiesMagazin erscheint als PDF, EPUB und HTML einmal monatlich.Erscheinungsdatum: 6. November 2016
Kontakt | |
| Postanschrift | freiesMagazin |
| c/o Dominik Wagenführ | |
| Beethovenstr. 9/1 | |
| 71277 Rutesheim | |
| Webpräsenz | http://www.freiesmagazin.de/ |
|
Autoren dieser Ausgabe | |
| Mirko Lindner | KeeWeb: Passwörter sicher speichern |
| Mathias Menzer | Der Oktober im Kernelrückblick |
| Jakob Moser | Spieltipp: Don't take it personally, babe, it just ain't your story |
| Holger Reibold | Scribus in der Praxis |
| David Schroff | Verschlüsselte Server-Backups mit Duply und Duplicity, Test: Life is Strange – Emotionale Zeitreise |
| Sujeevan Vijayakumaran | Rezension: Scrum |
| Dennis Weller | Test: The Curious Expedition – ein Roguelike-Abenteuer für Forscher und Entdecker |
|
Redaktion | |
| Dominik Wagenführ (Verantwortlicher Redakteur) | |
| Kai Welke | |
|
Satz und Layout | |
| Benedict Leskovar | Kai Welke |
|
Korrektur | |
| Frank Brungräber | Vicki Ebeling |
| Stefan Fangmeier | Mathias Menzer |
| Christian Schnell | Karsten Schuldt |
|
Veranstaltungen | |
| Ronny Fischer | |
|
Logo-Design | |
| Arne Weinberg (CC-BY-SA 4.0 Unported) | |
Soweit nicht anders angegeben, stehen alle Artikel, Beiträge und Bilder in freiesMagazin unter der Creative-Commons-Lizenz CC-BY-SA 4.0 International. Das Copyright liegt beim jeweiligen Autor. Die Kommentar- und Empfehlen-Icons wurden von Maren Hachmann erstellt und unterliegen ebenfalls der Creative-Commons-Lizenz CC-BY-SA 4.0 International. freiesMagazin unterliegt als Gesamtwerk der Creative-Commons-Lizenz CC-BY-SA 4.0 Unported mit Ausnahme der Inhalte, die unter einer anderen Lizenz hierin veröffentlicht werden. Das Copyright liegt bei Dominik Wagenführ. Es wird erlaubt, das Werk/die Werke unter den Bestimmungen der Creative-Commons-Lizenz zu kopieren, zu verteilen und/oder zu modifizieren. Die xkcd-Comics stehen separat unter der Creative-Commons-Lizenz CC-BY-NC 2.5 Generic. Das Copyright liegt bei Randall Munroe.
File translated from TEX by TTH, version 4.08.
On 6 Nov 2016, 12:32.