Zur Version ohne Bilder
freiesMagazin Juni 2014
(ISSN 1867-7991)
Ubuntu und Kubuntu 14.04 LTS
Ubuntu 14.04 LTS „Trusty Tahr“ ist die neue, fünf Jahre lang unterstützte Version von Ubuntu. Der Artikel soll helfen, zu entscheiden, ob es sich lohnt, die nächsten fünf Jahre auf „Trusty Tahr“ zu setzen. Daneben wird auch noch ein Blick auf Kubuntu, das KDE als Desktop-Umgebung einsetzt, geworfen. (weiterlesen)
GPS: Tracks und Routen erstellen mit QLandkarte GT
Mit dem Programm QLandkarte GT ist es möglich, auf der Grundlage der Karten von OpenStreetMap Tracks und Routen zu generieren und diese auf ein GPS-Gerät zu exportieren. Die Möglichkeiten der Software sind sehr vielfältig, deshalb erschließen sich dem Einsteiger nicht sofort die wichtigsten Funktionen. Ziel des Artikels ist es deshalb, dem Neuling einen schnellen Einstieg zu verschaffen. (weiterlesen)
Professionelles Database Publishing
Es gibt eine Reihe von Dokumenten, die sich nur schwer mit freier Software erstellen lassen. Für normale Texte wie Bücher oder Abschlussarbeiten gibt es LibreOffice und LaTeX, für Zeitschriftensatz (DTP) gibt es beispielsweise Scribus. Doch vollautomatisch aus Datenbanken erzeugte Dokumente lassen sich oft nur schwer mit den genannten Programmen erzeugen. Hier soll der „speedata Publisher“ helfen, der in diesem Artikel vorgestellt wird. (weiterlesen)
Zum Index
Linux allgemein
Ubuntu und Kubuntu 14.04 LTS
Der Mai im Kernelrückblick
Anleitungen
GPS: Tracks und Routen erstellen mit QLandkarte GT
Torify: Programme im Terminal anonymisieren
Kurztipp: Suchen und Finden mit ack statt grep
Software
Professionelles Database Publishing
Äquivalente Windows-Programme unter Linux – Teil 5: Internet-Programme (2)
Review: Papers, Please
Community
Rezension: Vim in der Praxis
Rezension: Wissenschaftliche Arbeiten schreiben mit LaTeX
Rezension: Clean Coder
Magazin
Editorial
Leserbriefe
Veranstaltungen
Vorschau
Konventionen
Impressum
Zum Index
Icon-Wettbewerb
Wir haben Anfang Mai einen kleinen Wettbewerb
ausgeschrieben, bei dem es darum ging, neue Icons für das Magazin zu
gestalten. Das Ergebnis können Sie seit dieser Ausgabe bewundern, dess
es gibt von nun an am Ende jedes Artikels zwei Icons mit Links, über die
man den Artikel sowohl weiterempfehlen als auch kommentieren kann.
Die Teilnehmerzahl hielt sich zwar sehr in Grenzen, aber immerhin zwei
kreative Geister haben sich auf den Aufruf gemeldet.
Gewonnen [1]
hat den Icon-Wettbewerb Maren Hachmann – sie hat damit ein Buch im Wert
von 40 Euro von uns zugeschickt bekommen. Wir bedanken uns auch beim
Zweitplatzierten, Berhard Haas, der eine Doppel-CD des „Free! Music!
Sampler 2013“ erhalten hat.
Layouter gesucht
Immer mal wieder gibt es Umstrukturierungen in unserem Team, und uns
haben in den letzten Monaten einige Layouter verlassen, sodass wir nun
wieder etwas Verstärkung benötigen.
Für Satz und Gestaltung des freiesMagazin benutzen wir
LaTeX [2], sodass
etwas Wissen auf diesem Gebiet bestimmt nicht schaden kann. Das Magazin
ist aber so gehalten, dass sehr viel mit Makros gearbeitet wird und
nicht zwingend LaTeX-Profis gefordert sind, um das Magazin zu
setzen. Außerdem wird das Grundgerüst von einem Skript erledigt, sodass
es nur um die „Feinarbeit“ des Artikels geht. Als Layouter muss man die
Bilder an die richtige Stelle im Text setzen und, um schöne Umbrüche
oder Textverteilung zu erreichen, auch mitunter selbst einmal etwas am
Text ändern. Diese Eigenschaft und ein Auge für gutes Layout sind uns
daher wichtiger als alle LaTeX-Kenntnisse.
Kenntnisse im Umgang mit Subversion (SVN) sind gut, aber nicht zwingend
erforderlich, da die wenigen benötigten Befehle schnell erlernt sind.
Zusätzlich stehen in den meisten Linux-Distributionen auch grafische
Oberflächen für die Verwaltung bereit, sodass man nicht zwingend die
Konsole bedienen muss.
Wenn Sie nun Interesse daran bekommen haben, freiesMagazin mitzugestalten und zu
verbessern, schreiben Sie uns doch eine E-Mail an  .
Und nun wünschen wir Ihnen viel Spaß mit der neuen Ausgabe!
Ihre freiesMagazin-Redaktion
Links
.
Und nun wünschen wir Ihnen viel Spaß mit der neuen Ausgabe!
Ihre freiesMagazin-Redaktion
Links
[1] http://www.freiesmagazin.de/20140524-gewinner-des-icon-wettbewerbs
[2] http://de.wikibooks.org/wiki/LaTeX-Kompendium
 Beitrag teilen
Beitrag teilen  Beitrag kommentieren
Beitrag kommentieren
Zum Index
von Hans-Joachim Baader
Ubuntu 14.04 LTS „Trusty Tahr“ ist die neue, fünf Jahre lang unterstützte
Version von Ubuntu. Der Artikel soll helfen, zu entscheiden, ob es sich
lohnt, die nächsten fünf Jahre auf „Trusty Tahr“ zu setzen.
Redaktioneller Hinweis: Der Artikel „Ubuntu und Kubuntu 14.04 LTS“ erschien erstmals bei
Pro-Linux [1].
Vorwort
Planmäßig erschien Ubuntu 14.04 LTS „Trusty Tahr“ ein halbes Jahr nach
Version 13.10 (siehe freiesMagazin
12/2013 [2]). Die neue
Version, die fünf Jahre lang mit Updates versorgt wird, hatte vor allem
Stabilität zum Ziel. Die Neuerungen gegenüber der Vorversion halten sich
daher in Grenzen. Zahlreiche
Software-Updates gab es trotzdem, aber kaum eines davon stellt einen großen
Bruch mit der Vorversion dar. Ansonsten wurde besonders daran gearbeitet,
die Distribution zu verfeinern und zu polieren.
Mit Ubuntu wurden auch Ubuntu Kylin, Ubuntu Server, die Cloud-Images, Ubuntu
Touch und die von der Gemeinschaft gepflegten Varianten Kubuntu, Ubuntu
GNOME, Xubuntu, Lubuntu, Edubuntu und UbuntuStudio veröffentlicht. Leider
können diese alle nicht Gegenstand des Artikels sein. Dieser wird sich auf
Ubuntu und Kubuntu beschränken.
Wie immer sei angemerkt, dass es sich hier nicht um einen Test der
Hardwarekompatibilität handelt. Es ist bekannt, dass Linux mehr Hardware
unterstützt als jedes andere Betriebssystem, und das überwiegend bereits im
Standard-Lieferumfang. Ein Test spezifischer Hardware wäre hier zu aufwendig.
Falls man auf Hardware-Probleme stößt, stehen die
Ubuntu-Webseiten zur Lösung bereit.
Da eine Erprobung auf realer Hardware nicht das Ziel des Artikels ist,
werden für den Artikel zwei identische virtuelle Maschinen, 64 Bit, unter
KVM mit jeweils 1024 MB RAM verwendet. In der ersten wurde Ubuntu
installiert, in der anderen Kubuntu.
Installation
Die Installation von Ubuntu ist wieder eine Freude, denn sie geht
schneller und einfacher vonstatten als bei den meisten anderen
Distributionen. Wenn man die Standardeinstellungen verwendet, ist sehr
schnell ein lauffähiges System installiert. Das genügt für Tests und andere
Bedürfnisse. Für spezielle Anforderungen stehen aber auch die
entsprechenden Optionen bereit, allerdings wird es dann aufwendiger.
Die einfachste Installation bietet ein Live-System, das als ISO-Image bereitsteht. Dieses „Desktop-Image“ ist 1,0 GB groß und kann auf
DVD oder einem USB-Medium verwendet werden.
Das Installationsprogramm Ubiquity bietet ähnlich wie der Debian-Installer
oder Anaconda von Fedora alle Möglichkeiten an, die Festplatten zu
partitionieren und das System darauf zu installieren. Die gesamte Festplatte
oder einzelne Partitionen können verschlüsselt werden, und LVM wird
unterstützt, auch in Form einer automatischen Partitionierung.
Sehr peinlich für eine Distribution, die sich an die Massen richtet, ist die
Installationsanleitung [3],
in der ausdrücklich darauf hingewiesen wird, dass sie veraltet
und möglicherweise irreführend ist. Informationen über Änderungen im
Installer lassen sich daraus folglich nicht gewinnen.
Installation von Ubuntu 14.04 LTS.
Eine Installation sollte gelingen, wenn wenigstens 512 MB Speicher für die
Desktop-Version bzw. 256 MB beim Server vorhanden sind. Unter Umständen soll
eine Installation mit 64 MB RAM bereits gelingen. Zu empfehlen sind jedoch
auf dem Desktop mindestens 1 GB, sodass alle benötigten Anwendungen
zugleich ohne zu swappen laufen können, denn nur so läuft das System
vollständig flüssig.
Hier soll nur die Installation von der Desktop-DVD kurz vorgestellt werden.
Standardmäßig wird nur eine einzige große Partition mit dem Dateisystem ext4
sowie eine Swap-Partition angelegt. Wenn man LVM einsetzt, kommt noch eine
230 MB große ext2-Partition für /boot hinzu. Will man seine
Partitionierung selbst definieren, muss man „Etwas anderes“ auswählen,
wodurch das Partitionierungswerkzeug gestartet wird. Dort können die
gängigen Dateisysteme einschließlich Btrfs ausgewählt werden.
Direkt nach der Definition der Partitionen beginnt der Installer mit der
Partitionierung und der Installation der Pakete im Hintergrund. Ein
Fortschrittsbalken zeigt von hier an den Stand der Installation an. Parallel
dazu kann man die Zeitzone auswählen und danach das gewünschte
Tastatur-Layout einstellen.
Im letzten Schritt gibt man seinen Namen, Anmeldenamen, Passwort und den
Computernamen ein. Wenn zuvor bereits per DHCP ein Name ermittelt werden
konnte, wird dieser als Vorgabe angezeigt. Wenn erkannt wird, dass die
Installation in einer virtuellen Maschine läuft, wird dagegen der Name
benutzer-virtual-machine vorgegeben. Optional können Daten im
Home-Verzeichnis verschlüsselt werden. Während man das Ende der Installation
abwartet, kann man nun noch einige Tipps zu Ubuntu ansehen. Zusammengefasst
wurde die Installation optisch an die neue Version angepasst, weitere
Änderungen sind nicht offensichtlich.
Tastatureinrichtung bei der Installation.
Ausstattung
Sowohl Ubuntu als auch Kubuntu starten ähnlich schnell wie in den
Vorversionen. Ubuntu (nicht aber Kubuntu) setzt eine
Hardware-3-D-Beschleunigung voraus, die bei Grafikkarten, die das nicht
bieten, durch llvmpipe emuliert wird. Bei einer ausreichend schnellen CPU
ist das Verfahren von der Geschwindigkeit her immer noch gerade so erträglich.
Das Grafiksystem ist bei X.org 7.7 geblieben, da es in der Zwischenzeit keine neue Version von
X.org gab. Allerdings wurden einige Komponenten
aktualisiert, darunter der X-Server 1.15.1 und Mesa 10.1. Unity liegt
in Version 7.2 vor.
Unter den größten Änderungen seit Ubuntu 13.10 findet sich der Linux-Kernel,
der auf Version 3.13.9 aktualisiert wurde. Der Standard-I/O-Scheduler wurde
von CFQ nach Deadline geändert. Der Energieverwaltung wurde weiterhin viel
Aufmerksamkeit gewidmet. AppArmor wurde weiter verbessert und ARM-Kernel
unterstützen jetzt mehrere Plattformen. Die Architekturen ARM64 und Power
werden jetzt vollständig unterstützt, ebenso das X32-ABI. Daneben enthält
der Kernel viele neue Treiber sowie Features, die nur für Spezialisten von
Interesse sind.
Das Init-System Upstart enthält in Version 1.12.1 einige Neuerungen,
darunter die Initiierung von
Benutzersitzungen [4].
Für Entwickler stehen GCC 4.8.2, Python 2.7.6 und 3.4.0, OpenJDK 6b31,
7u55 und vieles mehr bereit. Python 3.4 ist dabei die standardmäßig
installierte Version von Python, doch da sowohl innerhalb des Ubuntu-Archivs
als auch außerhalb noch viele Pakete auf Python 2 beruhen, ist auch die
ältere Version noch installierbar.
Neu ist Oxide, eine auf Chromium beruhende Bibliothek zur Darstellung von
Web-Inhalten. Ubuntu hat diese Bibliothek geschaffen, um Entwickler mit
einer fünf Jahre lang stabil gehaltenen Web-Engine zu versorgen, und
empfiehlt allen Entwicklern, sie anstelle von anderen Bibliotheken zu
verwenden.
Wie gewohnt hat Root keinen direkten Zugang zum System, sondern die Benutzer
der Gruppe sudo können über das Kommando sudo Befehle als Root ausführen.
Der Speicherverbrauch von Unity wurde offenbar etwas reduziert. Rund 520 MB
benötigt die Umgebung allein, ohne dass irgendwelche produktive Software
gestartet wurde. Die Reduktion wurde hauptsächlich dadurch erreicht, dass
Compiz statt 365 MB nur noch 215 MB benötigt. KDE benötigt in der
Standardinstallation mit einem geöffneten Terminal-Fenster etwa 500 MB. Ein
Teil dieses Speichers wird allerdings in den Swap ausgelagert, sodass
zusätzliches RAM frei wird. Die Messung des Speicherverbrauchs der Desktops
kann jeweils nur ungefähre Werte ermitteln, die zudem in Abhängigkeit von
der Hardware und anderen Faktoren schwanken. Aber als Anhaltspunkt sollten
sie allemal genügen.
Login-Prompt von Ubuntu 14.04 LTS.
Unity
Unity, die offizielle Desktopumgebung von Ubuntu, wurde von Version 7.1 auf
7.2 gebracht. Größere Änderungen gab es auch hier nicht, alles konzentrierte
sich auf die Stabilisierung des Erreichten. Das Menü eines Programms, das
bisher im globalen Menü angezeigt wurde, kann jetzt optional auch in der
Titelleiste des Programmfensters eingeblendet werden. Diese
Einstellung [5]
ist etwas versteckt in den persönlichen Einstellungen im Tab „Behavior“ der
„Appearance“-Einstellungen. Auch wenn bei vielen Programmen die Menüleiste
wieder gut in Unity integriert ist und die Option, die Menüs in die
Titelleiste zu bringen, wieder näher am gewohnten Verhalten ist, gibt es
aber noch genug Benutzer, die
die Menüs dort haben wollen, wo sie
hingehören, nämlich im Programmfenster. Dieses Verhalten kann man mit dem
unity-tweak-tool wieder herstellen.
Unity skaliert jetzt je nach verwendetem Monitor und soll damit auch auf
Monitoren mit sehr hoher Pixeldichte gut benutzbar sein, ohne dass man die
Größe von Hand hochsetzen muss. Die Optik wurde noch ein wenig nachjustiert;
so sind die Fenster-Titelleisten jetzt abgerundet. Eingabemethoden und
Tastaturbelegungen lassen sich jetzt leichter ändern und das schnelle
Wechseln zwischen verschiedenen Methoden und Belegungen ist möglich.
Die Suchfunktion von Unity umfasst weiterhin standardmäßig auch Online-Shops
und andere Online-Quellen, die jetzt parallel durchsucht werden, um die
Ergebnisse schneller zu erhalten. Tolerierbar ist die Internet-Suche ebenso
wenig wie zuvor. In den meisten Fällen ist sie lästig und nutzlos und sollte
abgeschaltet werden. Das Deaktivieren der Funktion ist weiterhin über einen
Schalter in den Systemeinstellungen unter der Kategorie „Privatsphäre“
möglich. Einzelne Linsen lassen sich wohl nur durch ihre Deinstallation
deaktivieren.
Dash mit Online-Suchergebnissen.
Die Suchergebnisse können jetzt nach Kategorie und Quelle gefiltert werden.
Neu ist eine Linse für die Fotosuche. Ein Rechtsklick auf gefundene
Elemente
zeigt erweiterte Informationen zu diesen, allerdings nicht als Popup oder
Tooltip, sondern
sondern durch Beiseiteschieben der anderen Fensterbereiche. Eine
neue Linse für Suchergebnisse von Nachrichten aus sozialen Netzwerken, der
„Freunde“-Bereich [6],
kam hinzu.
Filtern der Suchergebnisse in der Dash.
Neu ist auch das von GNOME kommende Adressbuch „Kontakte“, das Adressen und
Online-Konten verwalten kann. Der Standard-Webbrowser in Ubuntu ist Firefox
28.0, nun bereits aktualisiert auf 29.0. LibreOffice ist in Version 4.2.3.3
vorinstalliert. Für E-Mails ist Thunderbird 24.5 zuständig. Die sonstigen
installierten Programme sind im Wesentlichen die Standard-Programme von
GNOME, die zumindest grundlegend die häufigsten Aufgaben abdecken. In den
meisten Fällen bieten sie gerade einmal Grundfunktionen, sodass man sich
gerne nach leistungsfähigeren Programmen im Software-Center umsieht.
Software-Updates und das Software-Center funktionieren weiter wie gewohnt,
hier scheint sich in den letzten Monaten nichts geändert zu haben. Bei der
Konfigurierbarkeit von Unity kamen immerhin ein paar Optionen hinzu, sodass
man den Desktop mit etwas Mühe zumindest annähernd so definieren kann, wie
man es bevorzugt. Das hauptsächliche Mittel zum Zweck ist dabei
unity-tweak-tool, das man allerdings erst nachinstallieren muss. Noch
mehr Einstellungen, jedoch eher für Experten, bieten
compizconfig-settings-manager (ccsm) und dconf-tools.
KDE
Im Gegensatz zu Unity fühlt man sich bei KDE sofort heimisch. Hier gibt es
keine sinnlos verschobenen Menüs, Buttons oder gar von Dilettanten neu
entwickelte
Bildschirmschoner [7].
In Kubuntu 14.04 [8]
findet man KDE SC 4.13 vor.
Desktop von Kubuntu.
KDE SC 4.13 bringt eine neue semantische Suche sowie weitere neue Funktionen
in den Anwendungen. Nepomuk ist damit ein Auslaufmodell, bleibt aber
erhalten, um die Kompatibilität zu wahren. Anwendungen, die die neue Suche
nutzen wollen, müssen angepasst werden. Für die meisten mitgelieferten
Anwendungen in KDE SC 4.13 ist das bereits geschehen. Sonstige neue
Funktionen sind nur in den Anwendungen zu verzeichnen, da die KDE-Plattform
und der Plasma-Desktop bis auf Fehlerkorrekturen nicht mehr geändert werden.
Somit sollte KDE stabiler als je zuvor laufen.
Erstmals installiert Kubuntu Firefox 28 als Standard-Browser – bisher
erfüllte Rekonq diese Funktion. GStreamer 1.2 wird als Multimedia-Bibliothek
verwendet, nachdem alle Anwendungen entsprechend angepasst wurden (die
gstreamer-1.0-Pakete enthalten GStreamer 1.2.3). Ein neuer
„Treiber-Manager“ ersetzt das Programm „Zusätzliche Treiber“. Damit kann man
grafisch den gewünschten Treiber für eine Hardware auswählen, wenn es
mehrere Optionen gibt. Auch proprietäre Treiber werden mit einbezogen.
Firefox 29 unter Kubuntu.
Weitere Neuerungen sind die Plug-in-Installation im Bildbetrachter Gwenview,
ein Konfigurationsmodul für Touchpads, KDE Instant Messaging 0.8
beta1, verbesserte Konfiguration der Ländereinstellungen, Plasma Network
Manager 0.9.3.3, das KDE Software Development Kit, Verbesserungen im USB
Creator, KDE Connect 0.5.1 zur Verbindung mit einem Android-Smartphone,
automatische Absturzberichte, der IRC-Client Quassel 0.10 beta1 und neue
Systembenachrichtigungen.
Als Musik-Player ist Amarok 2.8 vorinstalliert, wie in Kubuntu 13.10. KDE
PIM mit Kontact ist in Version 4.13 installiert. Auch
LibreOffice und Krita
sind vorhanden. Weitere Anwendungen muss man aus den
Repositorien nachinstallieren.
Die Paketverwaltung Muon wurde auf Version 2.2 angehoben. Wesentliche
Änderungen gegenüber der Vorversion sind nicht zu erkennen, die in Kubuntu
13.10 noch vorhandenen Ungereimtheiten sind aber offenbar Geschichte.
Multimedia im Browser und auf dem Desktop
Nichts wesentlich Neues gibt es im Multimedia-Bereich. Firefox ist jetzt in
Version 29 enthalten. Mehrere Plug-ins zum Abspielen von Videos in freien
Formaten sind wie immer vorinstalliert, aber nicht in Kubuntu. Die
vorinstallierte Erweiterung „Ubuntu Firefox Modifications“ ist bei Version
2.8 geblieben. Weitere vorinstallierte Erweiterungen sorgen für die
Integration mit Unity und den Ubuntu-Online-Accounts.
Web-Videos dürften fast überall funktionieren, es sei denn, Flash ist im
Spiel. Bei Youtube funktioniert der HTML5-Modus ganz ohne Flash, allerdings
sind bei weitem nicht alle Videos in diesem Modus verfügbar. Andere
Webseiten zeigen gar keine
Videos, wenn sie kein installiertes Flash-Plug-in
vorfinden. Wenn man darauf angewiesen ist, kann man entweder das Adobe
Flash-Plug-in
in Firefox nachinstallieren, einen anderen Browser wählen oder
auf andere Methoden wie das Anschauen oder Herunterladen der Videos mit
anderen Programmen ausweichen. Die Tests wurden wegen der Langsamkeit von
Unity auf ein Minimum beschränkt; eine flüssige Video-Wiedergabe ist mit
llvmpipe schlicht nicht möglich.
Firefox 29.
Auf dem Unity-Desktop sollte in den bekannten Anwendungen Rhythmbox und
Filmwiedergabe (Totem) bei standardmäßig nicht unterstützten Formaten eine
Dialogbox erscheinen, die eine Suche nach passenden GStreamer-Plug-ins
ermöglicht und sie installiert. Das Verfahren ist wie immer äußerst
umständlich und führt nicht immer zum Erfolg. Daher ist es am besten, im
Software-Center gleich alle GStreamer-Plug-ins installieren, und vielleicht
noch andere Player wie VLC dazu. Auch für den Desktop gilt, dass eine
flüssige Video-Wiedergabe „dank“ llvmpipe nicht mehr möglich ist.
Unter KDE sieht es im Prinzip genauso aus, nur dass die Geschwindigkeit auch
ohne 3-D-Hardware akzeptabel ist. Amarok ist der Standard-Audioplayer.
Amarok oder Dragonplayer erkennen fehlende Plug-ins und starten die
Paketverwaltung, ähnlich wie bei GNOME. Sinnvoller ist es aber auch hier,
die GStreamer-Plug-ins schon vorab zu installieren.
Fazit
Mit Ubuntu 14.04 LTS haben Canonical und die Ubuntu-Gemeinschaft eine
Distribution geschaffen, die alle Linux-Anwender vom Einsteiger bis zum
Rechenzentren-Betreiber zufriedenstellen kann. Wie sich schon mit Ubuntu
13.10 abzeichnete, wurde der eingeschlagene Weg fortgesetzt und zu einem
soliden Abschluss gebracht, der jetzt fünf Jahre lang unterstützt wird,
sodass sich die Anwender mit nur wenigen Änderungen herumschlagen müssen.
Allerdings gilt auch für die LTS-Version: Nicht alles läuft am Anfang
bereits perfekt. Wer sichergehen will, nicht zu viele Probleme zu erleben,
sollte zumindest die Updates der ersten Wochen abwarten.
Eine Geschmacksfrage bleiben weiterhin die Entwicklungen von Ubuntu im
Desktop-Bereich. Doch selbst wenn man die angestrebte Konvergenz von
Desktop- und Mobiloberflächen für ausgemachten Mist hält, hat man immer noch
die Möglichkeit, die Konfiguration zu ändern und damit ein traditionell
bedienbares System zu erhalten. Letzten Endes lohnt es sich sowieso immer,
seinen Desktop so anpassen, dass man optimal damit arbeiten kann. Das
bedeutet, dass man in jedem Fall einige Zeit investieren wird, bei Ubuntu
nicht anders als bei anderen Distributionen.
Ubuntu, Kubuntu und die ganzen anderen Varianten sind und bleiben daher eine der
ersten Empfehlungen, wenn es um die Wahl einer Linux-Distribution geht. Nur
welche am Ende die beste Wahl ist, wird weiterhin mit heißen Köpfen diskutiert …
Links
[1] http://www.pro-linux.de/artikel/2/1683/ubuntu-und-kubuntu-1404-lts.html
[2] http://www.freiesmagazin.de/freiesMagazin-2013-12
[3] https://help.ubuntu.com/14.04/installation-guide/index.html
[4] https://wiki.ubuntu.com/TrustyTahr/ReleaseNotes/TechnicalOverviewUpstart
[5] https://help.ubuntu.com/14.04/ubuntu-help/unity-menubar-intro.html#app-menus
[6] https://help.ubuntu.com/14.04/ubuntu-help/unity-dash-friends.html
[7] http://www.heise.de/security/meldung/Ubuntu-schliesst-weitere-Luecken-im-Unity-Sperrbildschirm-2181210.html
[8] https://wiki.ubuntu.com/TrustyTahr/ReleaseNotes/Kubuntu
| Autoreninformation |
| Hans-Joachim Baader (Webseite)
befasst sich seit 1993 mit Linux. 1994 schloss er erfolgreich sein
Informatikstudium ab und ist einer
der Betreiber von Pro-Linux.de.
|
Beitrag teilen Beitrag kommentieren
Zum Index
von Mathias Menzer
Basis aller Distributionen ist der Linux-Kernel, der fortwährend
weiterentwickelt wird. Welche Geräte in einem halben Jahr unterstützt werden und
welche Funktionen neu hinzukommen, erfährt man, wenn man den aktuellen
Entwickler-Kernel im Auge behält.
Linux 3.15
Der April endete mit einer überschaubaren, dritten Entwicklerversion des
Linux-Kernels und im Mai wurde dieser Trend erst einmal fortgesetzt. Linux
3.15-rc4 [1] führt dann auch fast nur
Korrekturen auf und zeigt damit die Stabilisierungsphase des
Entwicklungszyklus an.
Die fünfte
Entwicklerversion [2] fiel dann wieder
etwas größer aus, obwohl er zwei Tage zu früh veröffentlicht wurde. Einen
guten Anteil daran haben Korrekturen an einem
CAN-Bus-Controller [3] von Bosch.
Außerdem findet sich hier eine schon länger erwartete Korrektur für einen
Fehler in dcache, dem Zwischenspeicher für Verzeichnisabfragen im Linux-
Dateisystem.
Nur ein bisschen kleiner fiel Linux
3.15-rc6 [4] aus, doch diesmal konnte der
vergleichsweise große Umfang mit der Zeitdifferenz von fast zwei Wochen gut
erklärt werden und relativiert die Verhältnisse wieder. Somit ist auch eine
der größten Änderungen die Rücknahme eines vorhergehendes Patches, der das
Batterie-Verzeichnis aus dem
/proc-Dateisystementfernte, weil es angeblich
nicht mehr benötigt wurde.
Nach dieser mitten in der Woche veröffentlichen
Entwicklerversion konnten sich nicht mehr viele Patches ansammeln, bis
Torvalds dann wieder am Sonntag den
-rc7 [5] vorlegte. Dass sich die überschaubare Zahl an Änderungen nicht in
der Zahl der geänderten Quelltextzeilen niederschlug, ist hauptsächlich einem
neuen Treiber für den
EtherCAT-Controller [6] von Industrie-PCs des
Herstellers Beckhoff geschuldet, der fast ein Viertel des Volumens ausmachte.
Die übrigen Änderungen stellten sich dann wieder als kleinere Korrekturen dar
und führten die weitere Stabilisierung des Entwicklung fort.
Pflege ohne Unterbrechung
Es liegt noch nicht lange zurück, dass sich verschiedene Distributoren –
namentlich SUSE und Red Hat – darin überschlugen, Methoden vorzustellen,
mittels derer der Linux-Kernel ohne Neustart und damit ohne Unterbrechung des
Betriebes mit Patches versehen werden kann (siehe „Der Februar im
Kernelrückblick“, freiesMagazin
03/2014 [7]).
Der Distributor
des CentOS-Derivates CloudLinux bietet nun mit KernelCare einen
kostenpflichtigen Service, der dies ebenfalls bewerkstelligen soll und neben
CloudLinux auch CentOS und RHEL unterstützt. Weitere Distributionen sollen
folgen [8]. Die Open-Source-Konkurrenz kGraft
und Kpatch wurden derweil für die Aufnahme in den Linux-Kernel vorgeschlagen
und werden bereits diskutiert.
Links
[1] https://lkml.org/lkml/2014/5/4/438
[2] https://lkml.org/lkml/2014/5/9/523
[3] https://de.wikipedia.org/wiki/Controller_Area_Network
[4] https://lkml.org/lkml/2014/5/21/610
[5] https://lkml.org/lkml/2014/5/25/138
[6] https://de.wikipedia.org/wiki/EtherCAT
[7] http://www.freiesmagazin.de/freiesMagazin-2014-03
[8] http://www.pro-linux.de/-0h215246
| Autoreninformation |
| Mathias Menzer (Webseite)
behält die Entwicklung des Linux-Kernels im Blick, um über kommende Funktionen
von Linux auf dem laufenden zu bleiben und immer mit interessanten Abkürzungen
und komplizierten Begriffen dienen zu können.
|
Beitrag teilen Beitrag kommentieren
Zum Index
von Andreas Müllhofer
Mit dem Programm QLandkarte GT ist es möglich, auf der Grundlage der Karten von
OpenStreetMap Tracks und Routen zu generieren und diese auf ein GPS-Gerät zu
exportieren. Die Möglichkeiten der Software sind sehr vielfältig, deshalb
erschließen sich dem Einsteiger nicht sofort die wichtigsten Funktionen. Ziel
des Artikels ist es deshalb, dem Neuling einen schnellen Einstieg zu
verschaffen.
QLandkarte [1] wird über den Paketmanager der
jeweiligen Linux-Distribution installiert, es ist standardmäßig in den Quellen
enthalten. Sollte Wine (eine Microsoft-Windows kompatible
Laufzeitumgebung) [2] noch nicht auf dem System laufen,
sollte man dieses Paket an dieser Stelle auch gleich zur Installation auswählen.
Nach der Installation von Wine werden die Dateien mit der Endung .exe beim Aufruf
mittels eines Dateimanagers (normalerweise Doppelklick) so geöffnet, als ob man
nicht unter Linux sondern unter Windows arbeiten würde. Es folgt also eine ganz
normale Installationsroutine, an deren Ende etliche Dateien in einem bestimmten
Verzeichnis abgelegt werden – dazu später mehr. Alternativ kann man die genannte
Installationsroutine auch über die Konsole aufrufen: wine Datei.exe
Beim ersten Aufruf des Routenplaners ist noch keine Karte enthalten. Davon
ausgehend, dass die Karten später für Touren auf einem GPS-Gerät zum Wandern
oder Radfahren benutzt werden sollen, bieten sich verschiedene Karten auf Basis
von OpenStreetMap [3] an, die für diese Zwecke
generiert
wurden [4] [5] [6].
Auch Karten speziell für Garmin-Navigationsgeräte sind via OpenStreetMap
verfügbar [7].
Die Karten von openmtbmap.org [8] werden für die verschiedensten Länder zum
Download angeboten, für Deutschland lassen sich auch noch speziell die
Bundesländer auswählen. Die heruntergeladene Datei (z. B. mtbayern.exe) ist eine
unter Windows ausführbare Datei, sie lässt sich unter Linux mit wine öffnen. Es
folgt ein Installationsprozess, an dessen Ende man mehrere img-Dateien sowie drei
verschiedene tdb-Dateien in einem Unterordner von ~/.wine/drive_c/Ordner hat.
(Der Punkt vor dem Ordnernamen macht es unsichtbar, dies also bitte bei der
Suche mit einem Dateimanager entsprechend berücksichtigen.) Im Falle der hier
erwähnten Bayern-Karte wählt man nun wieder mit QLandkarte im
Menü „Datei -> Karte Laden“ eine Datei mit der Endung .tdb und dann nachfolgend
nach Aufforderung die gleichnamige img-Datei.
Die drei tdb-Dateien unterscheiden sich übrigens wie folgt:
- c.tdb: Karte mit Höhenlinien
- x.tdb: Karte ohne Höhenlinien
- z.tdb: Nur Höhenlinien
Zum Test kann man seine Hausadresse eingeben, bzgl. Reihenfolge und Syntax
(Komma, Leerzeichen) erweist sich das Programm als ausgesprochen großzügig. Bei
fehlerhafter Schreibung allerdings passiert nichts, lediglich „kein Ergebnis“
erscheint unauffällig unter der Suchmaske. Sind Ort und Straße gleichnamig auf
der Karte gespeichert, erscheint das bekannte Standortsymbol (roter Punkt in
rotem Kreis) mit dem Text der Adresse darüber.
Erstellen von Touren
Eine mit QLandkarte entworfene Tour kann man entweder als Track oder Route
speichern bzw. auf ein GPS-Gerät exportieren. Im Folgenden sei kurz der
Unterschied zwischen Tracks und Routen erklärt.
Ein Track besteht aus der Aneinanderreihung von vielen Punkten entlang einer
Strecke, welche entweder von einem GPS-Gerät aufgezeichnet wurde oder aber mit
einem Routenplaner wie QLandkarte erstellt worden ist. Ein Track lässt sich
farblich markiert auf der Karte des GPS-Gerätes darstellen. Man kann ihn im
Rahmen einer Outdoor-Aktivität beispielsweise mit dem Rad nachfahren.
Allerdings gibt es dabei keine Signale von Seiten des Navis, welche auf ein
Abbiegen bzw. das Erreichen eines Wegpunktes hinweisen. Diese Funktion kann man aber
nutzen, wenn man die Strecke stattdessen als Route exportiert, welche allerdings
nicht mehr als 50 Punkte aufweisen darf, wenn sie auf einem Navi eingesetzt
werden soll.
Manuelles Erstellen von Tracks und Routen über Wegpunkte
Das Programm präsentiert sich mit der gängigen Anordnung von aufklappbaren Menüs
unter der oberen Fensterleiste. Ein Großteil des Bildschirms zeigt einen
Kartenausschnitt, dessen Maßstab je nach Bedarf mit Hilfe des Scrollrades der
Maus vergrößert oder verkleinert werden kann. Im linken Viertel des Bildschirms
befinden sich drei weitere Ansichten vertikal übereinander: Ein Hauptmenü mit
den wichtigsten Befehlen und deren Tastenkürzel auf einen Blick, darunter eine
Projektzusammenfassung und unten links ein Block mit mehreren Reitern.
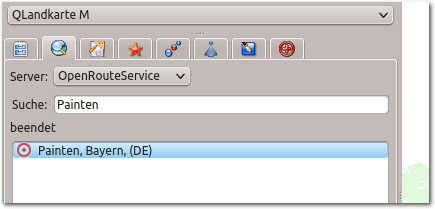
Der Reiter für das Suchfeld ist aktiviert, Ortseingabe unter „Suche:“.
Gleich der zweite Reiter zeigt eine Lupe, hier also findet sich das Suchfeld,
mit welchem sich Orte oder ganze Adressen eingeben lassen. Gleich nach dem
Suchvorgang sieht man auf der Karte
ein Standortsymbol eingezeichnet. Dieses
kann als erster Wegpunkt für eine Strecke fungieren. Dazu muss er aber noch als
solcher deklariert werden, indem man mit dem Mauszeiger darüber fährt. Sogleich
bildet sich ein etwas größerer Kreis darum, ein Klick auf das grünes Pluszeichen
macht aus unserer gesuchten Adresse endgültig einen Wegpunkt mit der Suchadresse
als Bezeichnung.
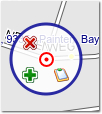
Der Kreis bildet sich um den Mauszeiger über dem Wegpunkt.
Weitere Wegpunkte erstellt man analog durch die Adress-Suche oder aber man
zeichnet sie manuell: Dazu drückt man mit der rechten
Maustaste auf eine gewünschte
Stelle in der Karte, sodass ein Menü aufklappt. Mit einem Klick auf das grüne
Pluszeichen wird ein weiterer Wegpunkt erstellt. Achtung: die Bezeichnung wird
automatisch vom vorigen Wegpunkt übernommen inkl. einer um eins erhöhten Zahl.
Wenn also der erste Wegpunkt „Musterstraße 14“ heißt, so wird der nächste ohne
Nachfrage als „Musterstraße 15“ bezeichnet. Man sollte in diesem Fall den
zweiten Wegpunkt anders benennen, z. B. kurz „W1“. Alle nachfolgenden Punkte
heißen dann W2, W3 usw. Ältere Versionen von QLandkarte verlangen übrigens nach
jeder Eingabe eines Wegpunktes noch die manuelle Eingabe eines Namens.
Es sei darauf hingewiesen, dass die Benennung der Wegpunkte später nicht für den
Verlauf der Strecke verantwortlich ist.
Die Reihenfolge wird an einer anderen Stelle
festgelegt. Fast in Nachbarschaft des Reiters „Suchen“ befindet sich der
Reiter „Wegpunkt“, der mit einem Stern gekennzeichnet ist. Wenn man diesen nun
anklickt, finden sich alle Wegpunkte aufgelistet. Es ist jetzt nicht nötig, alle
zu markieren, das geht später schneller. Ein Rechtsklick auf einen der Wegpunkte
öffnet ein Untermenü. Hier hat man die Möglichkeit, eine Route aus allen
aufgeführten Wegpunkten erzeugen zu lassen.
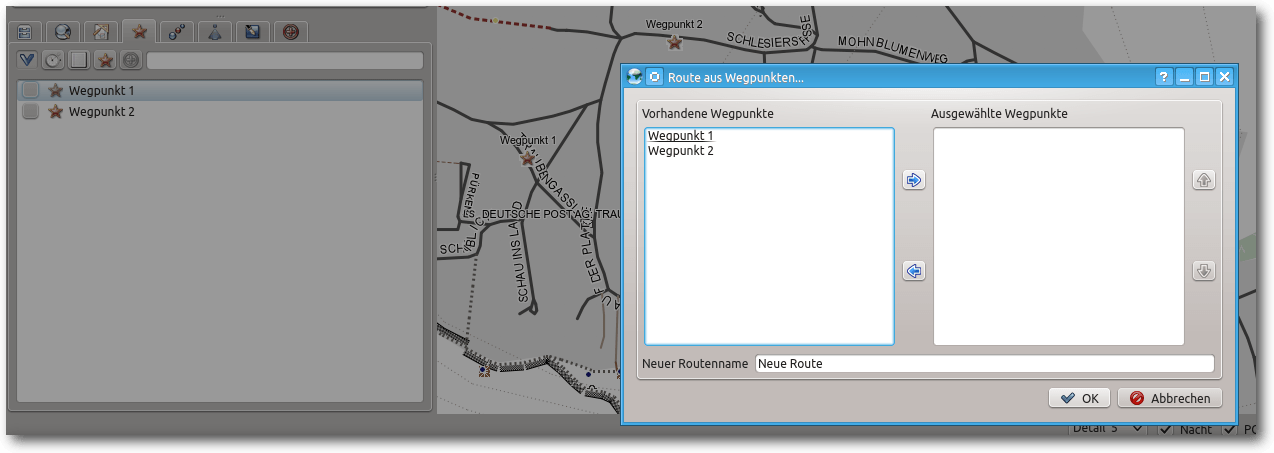
Nach dem Rechtsklick auf einen der Wegpunkte (links) öffnet sich das Menü zum Erzeugen einer Route.
Man kann jetzt bequem mit „Shift“ und linker Maustaste den ersten und letzten Eintrag
markieren und alle Punkte ins rechte Feld verschieben („Pfeilsymbol“).
Dort kann dann noch die Reihenfolge („Pfeil nach oben“ / „unten“) verändert
werden. Zum Schluss wird noch ein neuer Routenname eingegeben.
Zwei Dinge haben sich nach dem Abschluss der Aktion verändert: Zum einen sind
die Wegpunkte auf der Karte mit farbigen Linien verbunden, zum anderen ist jetzt
automatisch ein anderer Reiter („Routen“) aktiv. Sofern die Route an geraden
Straßen verläuft, sieht es ganz hübsch aus, aber sobald Kurven auftreten merkt
man, dass es sich zunächst nur um Luftlinien-Verbindungen handelt.
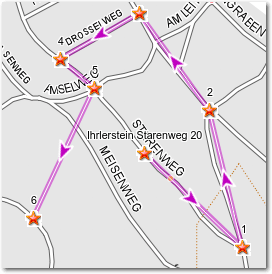
Die Wegpunkte sind mit geraden Luftlinien direkt miteinander verbunden.
Was jetzt noch fehlt ist die Berechnung der Route: Ein Rechtsklick auf den
bereits sichtbaren Reiter der erstellten Route bietet die Option „Route berechnen“
an. Daraufhin wird die Route dem Straßenverlauf folgen. Würde man
sie jetzt auf ein GPS-Gerät übertragen, würde das Navi genau bei den
erstellten Wegpunkten ein Signal bzw. einen Hinweis auf eine Richtungsänderung
geben.
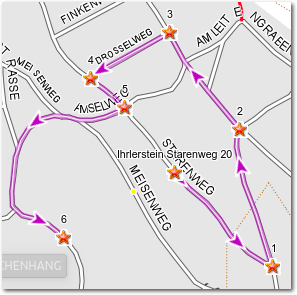
Nachdem die Route berechnet ist, folgen die Linien dem tatsächlichen Straßenverlauf.
Nun wird auch die tatsächliche Länge der Strecke angegeben und nicht nur die
aufsummierten Verbindungsvektoren zwischen den Wegpunkten. Ein Rechtsklick
auf den Eintrag „Route“ eröffnet nun auch die Möglichkeit, daraus noch einen Track
zu erzeugen bzw. ein Overlay zu erstellen.
Tracks und Routen automatisiert anlegen lassen
Das Erstellen von Tracks oder Routen ausschließlich über selbst erstellte
Wegpunkte ergibt dann Sinn, wenn man eine ganz spezielle Vorstellung von der
Strecke hat – etwa weil man beispielsweise zehn verschiedene Adressen in einem
Ort aufsuchen muss, um eine Sendung zu verteilen.
Will man dagegen mit dem Rad eine Strecke von 25 km von A nach B zurücklegen,
ist dies zu mühsam. Man will an die frische Luft und nicht zuvor stundenlang am
PC sitzen.
Deshalb gibt man jetzt Wegpunkte als Start- und Endpunkt ein – direkt oder über
die Ortssuche. Bevor man sich jetzt die Route berechnen lässt, sollte man einen
Blick auf das Register „Einstellungen“ werfen: man kann
nämlich wählen, ob man die Strecke mit dem Auto, Fahrrad, Mountainbike etc.
zurücklegt, ob man dabei lieber schnell sein will oder einer kürzeren Strecke
den Vorzug gibt. Dementsprechend unterschiedlich wird die Route berechnet. Man
kann dies immer wieder aufs Neue probieren und auf die Unterschiede achten. Nun
wird aber auch klar, welche Nachteile sich ergeben, wenn man eine derart
erstellte Route auf ein GPS-Gerät zum Radfahren überträgt: Das Gerät hat seine
eigene Software, seine eigenen Einstellungen, vielleicht eine andere Karte. So
kann es passieren, dass das Fahrradnavi vor einer Straße, einem Feldweg
etc. „stehen bleibt“ und einen Umweg fahren will, weil es die von QLandkarte
errechnete Strecke für die eingegebene Fortbewegungsart nicht nachvollziehen
kann. Immerhin könnte man als Routing-Option für das Navi „Fußgänger“
einstellen, dann werden eigentlich alle Straßen und Wege wie von QLandkarte
vorgeschlagen angenommen. Eine weitere Eigenheit der Route kann ebenfalls für
Unmut
sorgen: Nach erfolgtem Transfer auf das GPS-Gerät wird diese nicht
angenommen, weil – es wurde schon erwähnt – mehr als 50 Punkte darin enthalten
sind. Alternativ kann man auch mehrere Routenteilstücke erstellen und diese
nacheinander auf dem GPS-Gerät aufrufen.
Einfacher aber ist es, aus der berechneten Route einen Track zu erstellen. Denn
wenn man einmal seine Route berechnet hat, kann man mit einem Rechtsklick darauf
leicht noch einen Track und/oder ein Overlay erstellen. Dieser wird auf dem
GPS-Gerät – je nach Einstellung – als dickere farbige Linie dargestellt und kann
relativ bequem nachgefahren werden. Dies ist auch die gängige Praxis, im Netz
stehen jede Menge fertiger Tracks für Wanderer und Radfahrer zum Download zur
Verfügung.
Immerhin dürfte jetzt klar geworden sein, dass Routenplaner wie QLandkarte
primär auf das Erstellen von Tracks ausgerichtet sind. Ein sinnvolles Routing
wie man es vom „Auto-Navi“ gewohnt ist muss man dem GPS-Gerät selbst
überlassen. Entscheidend ist dann der Einsatz der richtigen Karte auf solchen
Geräten.
Erstellen von Tracks über den Entfernungsmesser
Es ist sicher reizvoll, sich eine längere Strecke per Mausklick und in
Sekundenschnelle berechnen zu lassen. Allerdings stellt man in der Praxis
schnell fest, dass manche Wege nicht wirklich gut befahrbar oder
schlichtweg fast nicht auffindbar
sind (Modus „Mountainbike“). Wie auch immer, es
kann Gründe dafür geben, sich die Tour Straße für Straße, den Blick auf die
Karte gerichtet,
selbst zu erstellen: Unter dem Menüpunkt „Overlay“ findet sich
der „Entfernungsmesser“. Einmal aktiviert, markiert das Tool (breiter lilafarbener
Strich) selbstständig die gesamte Straße auf welcher der Mauszeiger gerade ruht.
Mit der linken Maustaste setzt man dann jeweils einen Punkt, um die Straße zu
wechseln bzw. den Verlauf der Route festzulegen. Eine dünnere, rot punktierte
Linie zeigt an, wie der endgültige Verlauf aussehen wird. Ein Klick auf die
rechte Maustaste deaktiviert das Werkzeug wieder.
Informationen zur aktuellen Höhe im Track
Wenn man aus der erstellten Route einen Track erstellt, öffnet sich ein
Menü, das dem Anwender die Auswahl der Höheninformation anbietet.
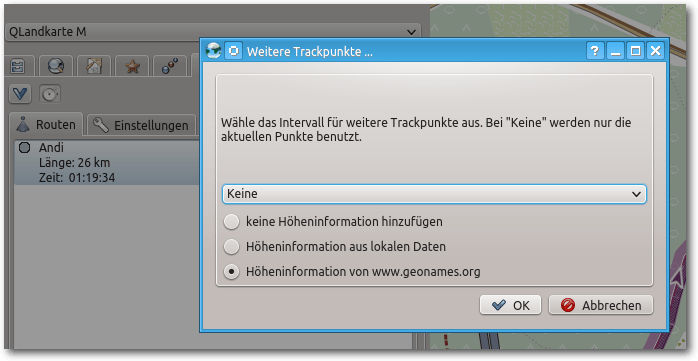
Nach einem Rechtsklick auf die Route und Klick auf „Track erzeugen“ öffnet sich ein Dialog zur Bestimmung der Höheninformation.
Wählt man den dritten Punkt – Höheninformationen von
geonames.org [9] – so kann man sich den ganzen
Track entlang die Höhenmeter angeben lassen: Mit einem einfachen Klick auf den
jetzt erstellten Track sieht man in der Karte bereits einen kleinen Kasten mit
dem Höhenprofil.
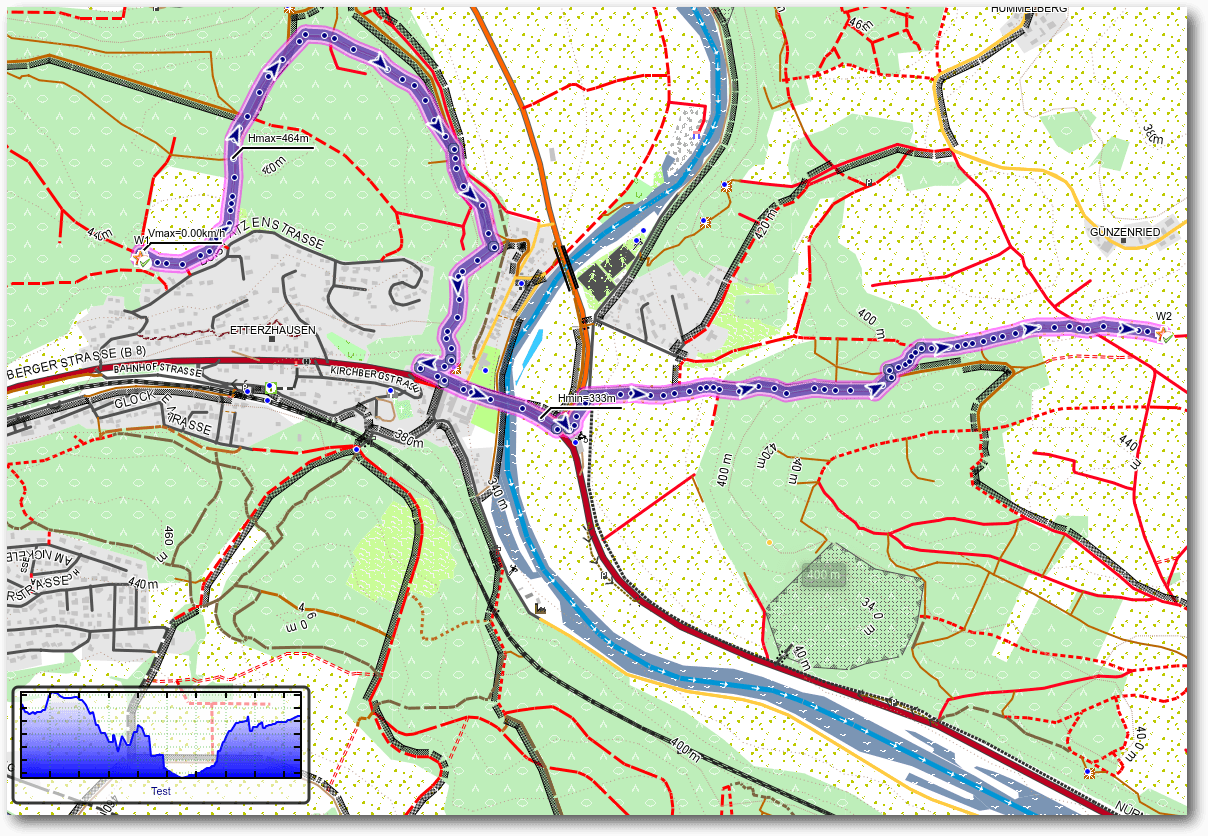
Man sieht jetzt den Kartenausschnitt mit Track und dem Höhenprofil zwischen Start- und Endpunkt.
Wird dieser angewählt, so wird die Kartenansicht durch ein detailliertes Profil
der Strecke ersetzt.
In einem Koordinatensystem sind für die y-Achse die
Höhenmeter und an der x-Achse die zurückgelegten Kilometer abzulesen. Fährt man
mit dem Mauszeiger über das Profil, so sieht man für jeden Punkt der Tour, in
welcher Höhe man sich befindet bzw. wie viele Meter Anstieg/Abfahrt man
bereits hinter sich hat. Außerdem kann man natürlich ablesen, wie viele Kilometer
man zurückgelegt bzw. noch vor sich hat. Des Weiteren lassen sich an beliebigen
Stellen der Grafik Wegpunkte anlegen (beispielsweise wenn man auf der Karte
betrachten will, wo denn diese besonders große Steigung ist), diese können dann
wieder auf der Karte angesehen werden.
Das Höhenprofil nach einem Klick darauf in vergrößerter Darstellung und detaillierten Informationen.
Vornehmen von Änderungen
Nachdem man eine längere Tour erstellt hat, kann es sein, dass man Track oder
Route noch nachbessern will, beispielsweise weil man feststellen konnte, dass
die Tour zu viele Steigungen enthält.
Hat man mit dem Entfernungsmesser eine Tour falsch fortgeführt, kann man
einzelne Punkte rückwirkend löschen, indem man sie markiert
(der Overlaymodus ist
aktiv) und einzeln durch
Klicken auf das rote Kreuzchen löscht.
Ist die Strecke
schon weit fortgeschritten und liegen die Fehler schon weiter
zurück, so wäre dieses Verfahren zu umständlich.
Also erstellt man – wenn nicht schon geschehen – mittels Rechtsklick auf das
Overlay einen entsprechenden Track. Diesen kann man nun zerschneiden: Dazu
aktiviert man im Hauptmenü „Track -> Track zerteilen“.
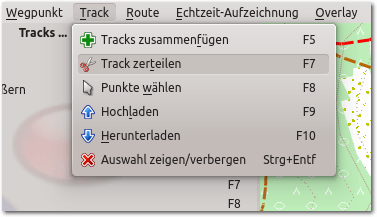
Im Hauptmenü Track anwählen und das Scherensymbol aktivieren.
Am Mauszeiger erscheint eine Schere, mit welcher man so über einen Punkt der
Strecke fährt, dass sich dieser Rot verfärbt und klickt einmal. Man hat nun in
der Trackliste einen weiteren Track. Diesen Vorgang wiederholt man, bis man drei
Tracks hat: zwei mit korrektem Verlauf und den Teil, welcher gelöscht werden
soll. Im Register „Tracks“ wird nun der fehlerhafte Verlauf gelöscht, indem er
in der Trackliste ausgewählt wird und man mit der rechten Maustaste das
Untermenü mit der Löschoption aufruft.
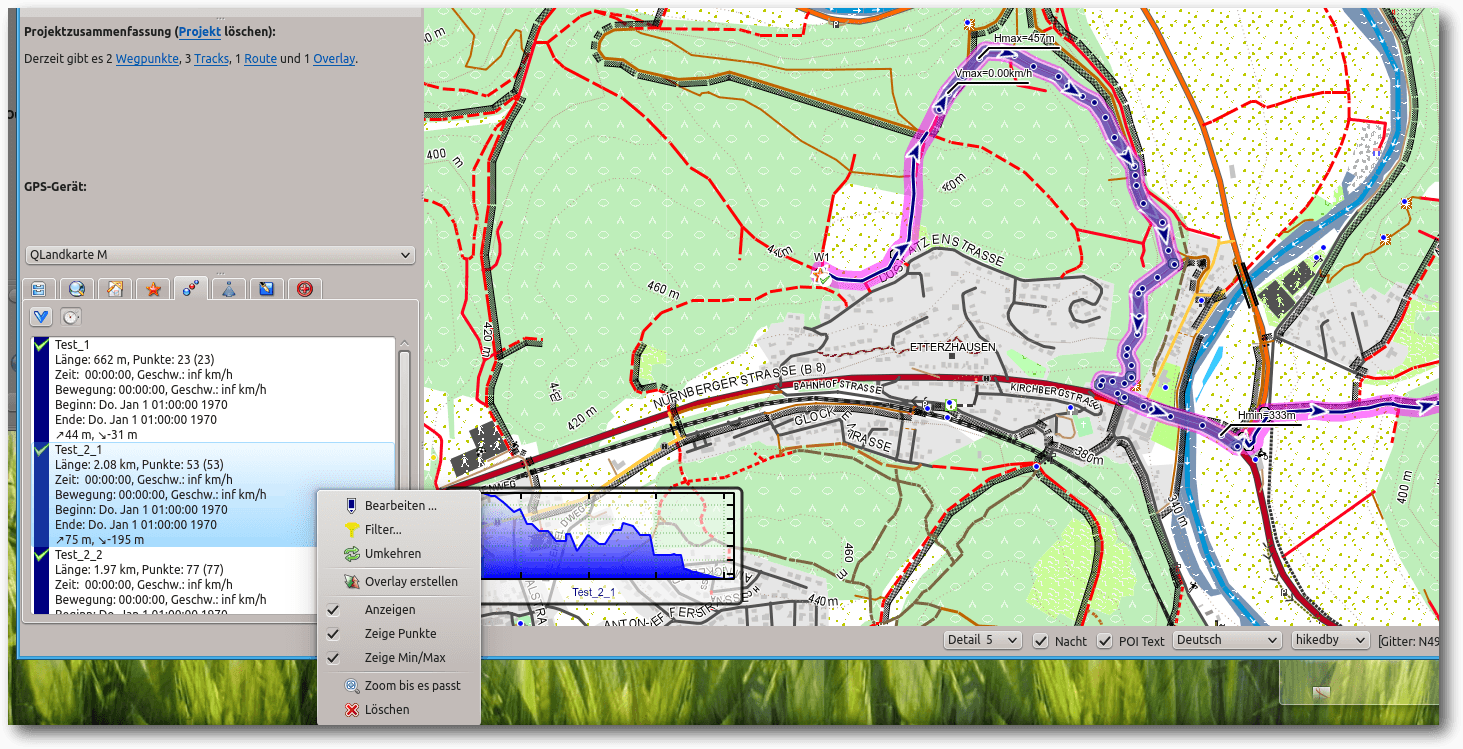
Im Trackfenster links ist nach dem Schneiden ein neuer Track (Test_2_1) entstanden, er fällt farblich und durch die Darstellung von Trackpunkten auf.
Danach wird mit dem Entfernungsmesser ein neues Overlay erstellt, in einen Track
umgewandelt
und schließlich durch „Track -> Track zusammenfügen“ wieder neu
eingebunden.
Bearbeiten eines Tracks
Klickt man mit der rechten Maustaste auf den Track im linken unteren Fenster, so
kann man ihn zur Bearbeitung öffnen. Auf all die Optionen einzeln einzugehen
würde den Umfang des Artikels sprengen. Hier kann jeder selbst nach Belieben ins
Detail gehen. Erwähnt sei trotzdem noch das Register „Trackliste“, welches alle
Punkte des Tracks aufführt, mit genauer Angabe von Position und Höhe. Über diese
Liste können einzelne Punkte gezielt versteckt oder gar gelöscht werden. Hat man
über der Trackliste die Ansicht „Karte“ gewählt, sieht man den gerade gewählten
Punkt mit einem roten Fadenkreuz markiert.
Trackpunkte auf Google Maps zeigen
Sehr reizvoll kann es sein, sich einen Trackpunkt über Google Maps in der
Satellitenansicht anzeigen zu lassen. Dazu wählt man den Track an und klickt
dann in der Karte mit der rechten Maustaste auf einen Punkt. Man wählt
„Trackpunktposition auf Google Maps anzeigen“.
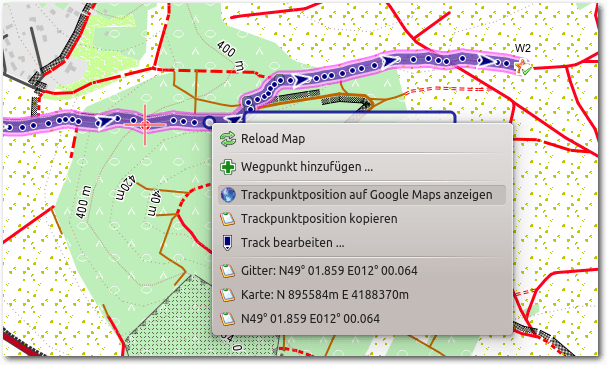
Nach einem Rechtsklick auf einen Trackpunkt öffnet sich ein Untermenü.
Es kann sein, dass sich kein Punkt anzeigen lässt. Dieser Fall tritt ein, wenn
bereits ein Overlay erstellt worden ist, dessen Ansicht aktiv ist. In diesem
Fall kann man einfach das Häkchen bei „Overlay -> Anzeigen“ entfernen.
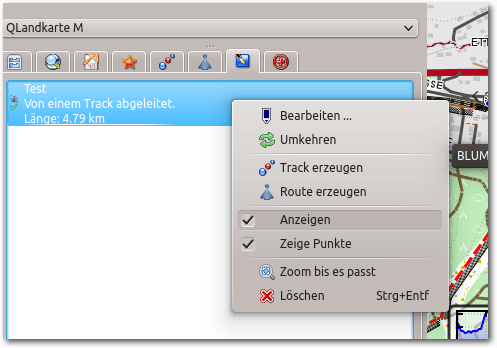
Der Reiter „Overlay“ ist aktiviert, bei „Anzeigen“ ist ein Haken, diesen muss man deaktivieren, wenn man an die Eigenschaften des Trackpunktes ran will.
Export auf ein GPS-Gerät
Wenn man die erstellten Touren auf dem GPS-Gerät einsetzen will, muss man die
Exportfunktion des Programms in Anspruch nehmen. Man sucht und findet eine
derartige Funktion im Menü „Datei -> Geodaten exportieren“. Es öffnet sich der
übliche Dialog zum Speichern von Dateien, wobei man auch direkt auf das Navi
speichern kann. Nach der Wahl eines Dateinamens öffnet sich ein weiterer Dialog.
Hier kann man seine Tracks,
Routen und Wegpunkte zum Export auswählen.
Exportiert werden die Dateien im gpx-Format. Im Netz finden sich viele
Tourenvorschläge. Sofern sie in diesem Format angeboten werden, kann man sie auf
sein GPS-Gerät übertragen.
Abschließende Hinweise
Für die Berechnung von Routen benötigt QLandkarte GT eine Internetverbindung. Es
kann auch vorkommen, dass die Server, auf welche Qlandkarte zurückgreift,
überlastet sind.
Eine Routenberechnung ist dann nicht möglich.
Nach einer
kurzen Wartezeit erscheint ein entsprechender Hinweis, auf der Karte bleibt die
„Luftliniendarstellung“ zwischen Start- und Endpunkt bestehen. In diesem Fall
kann man unter dem Reiter „Routen“ bei Einstellungen anstelle von
OpenRouteService die Karten von MapQuest anwählen. Dabei handelt es sich um eine
Gesellschaft, welche kostenlose Karten- und Routingdienste auf Basis
verschiedener kommerzieller und freier (OpenStreetMap) Geodaten anbietet.
Allerdings sind auf deren Server Kartenmaterial und Einstellungen (der Eintrag
Mountainbike fehlt ganz) weniger flexibel gestaltet.
Links
[1] http://www.qlandkarte.org/
[2] http://www.winehq.org/
[3] http://www.openstreetmap.org/
[4] http://openmtbmap.org/de/download/odbl/
[5] http://wiki.openstreetmap.org/wiki/User:Computerteddy
[6] http://wiki.openstreetmap.org/wiki/DE:All_in_one_Garmin_Map
[7] http://wiki.openstreetmap.org/wiki/DE:OSM_Map_On_Garmin/Download
[8] http://openmtbmap.org/de/
[9] http://www.geonames.org
| Autoreninformation |
| Andreas Müllhofer
hat vor etwa zwölf Jahren begonnen mit diversen Linux-Distributionen zu
experimentieren, seit acht Jahren arbeitet er ausschließlich unter diesem
Betriebssystem.
|
Beitrag teilen Beitrag kommentieren
Zum Index
von Christian Imhorst
Die meisten Menschen benutzen Tor vermutlich zum anonymen Surfen mit dem Tor
Browser Bundle, das in freiesMagazin
05/2014 [1] vorgestellt
wurde. In diesem Artikel geht es um die Nutzung von Tor im Terminal, was je
nach Distribution mit mehr oder weniger Installationsaufwand verbunden ist.
Tor installieren
Der Name Tor ist eine Abkürzung für The Onion
Router [2]. Das Ziel von Tor ist,
Verbindungsdaten von Programmen im Internet zu anonymisieren und nicht nur
TCP-Verbindungen von Webbrowsern, sondern auch die von E-Mail-Programmen,
SSH und anderen Anwendungen zu verschleiern. Zusätzlich verbirgt Tor den
Standort des Nutzers und schützt vor Netzwerküberwachung und der Analyse
des Datenverkehrs.
Unter Debian reicht z. B. die Installation von Tor aus den
Paketquellen. Die Installation aus dem Repository spielt zwar nicht
unbedingt die aktuelle Version auf die Festplatte, aber immerhin werden
wichtige Sicherheitsupdates nachgeliefert. Von der Installation aus dem
Repository von Ubuntu dagegen raten die Entwickler ab. Da das Programm
„universe“ [3] zugeordnet ist,
erhält es keine aktuellen Stabilitäts- und Sicherheitsupdates.
Für Debian und Ubuntu gibt es aber auch ein Tor-Repository, das man direkt
in eine Source-Liste eintragen und mit dem Paketmanager installieren
kann [4]. Dieses Vorgehen ist
besonders zu empfehlen, da so immer die aktuellste Version und die neuesten
Sicherheitsupdates installiert werden.
Die beiden anderen Distributionen, die vom Tor-Projekt direkt mit Paketen
versorgt werden, sind Fedora und
CentOS [5]. Für sie gilt der
gleiche Hinweis wie für Ubuntu: Die Pakete in den Repositorys sind
veraltet. Für Yum wird aber ein Repository vom Tor-Projekt
selbst gepflegt.
Für openSUSE und andere Linux-Distributionen gibt es dagegen kein Repository
des Tor-Projekts, hier bleibt nur das Übersetzen des Quellcodes [6]:
$ ./configure
$ make
# make install
Wenn man wissen möchte, ob man die aktuelle Version von Tor verwendet,
gibt man einfach
den Befehl tor ins Terminal ein, um Tor manuell zu starten. Zu der Zeit, als
dieser Artikel geschrieben wurde, war die neuste Version 0.2.4.21:
$ tor
Mar 25 20:25:41 [notice] Tor v0.2.4.21
Tor benutzen
Egal, wie man Tor installiert hat, in den Voreinstellungen ist Tor immer
als Client konfiguriert und die Konfigurationsdatei muss in der Regel auch
nicht geändert werden. Tor ist gleich nach der Installation und dem ersten
Start einsatzbereit. Für diesen Artikel werden aber zur Veranschaulichung
trotzdem zwei Einstellungen in der Konfigurationsdatei /etc/tor/torrc
geändert. Hierfür muss man die Datei mit Root-Rechten editieren.
Zuerst wird dort die Zeile für die Einstellung ControlPort auskommentiert, also das
Doppelkreuz davor entfernt:
ControlPort 9051
Damit wird der Port gesetzt, auf dem Tor auf lokale Verbindungen lauscht.
Danach wird Tor noch mitgeteilt, dass sich Anwendungen nicht
authentifizieren müssen, um Tor zu kontrollieren. Dazu wird die Zeile mit
CookieAuthentication auskommentiert und die 1 durch eine 0 ersetzt:
CookieAuthentication 0
Auf die letzte Einstellung sollte man verzichten, wenn Tor auf einem Server
läuft oder der Rechner mehrere Benutzer hat, da sonst jeder Kontrolle über
die Tor-Installation auf dem System erlangen kann. Weiter unten wird aber
gezeigt, wie die Authentifizierung mit einem Passwort wieder sichergestellt
werden kann.
Nach der Änderung der Konfigurationsdatei muss Tor neu gestartet werden:
# /etc/init.d/tor restart
Bevor es weitergeht, wird erst einmal die aktuelle IP-Adresse im Terminal
festgestellt:
$ wget -qO- ifconfig.me/ip
82.185.27.13
Stellt man dem Befehl ein torify voran, bekommt man ein anderes Ergebnis:
$ torify wget -qO- ifconfig.me/ip
77.247.181.164
Das Skript torify ist ein Wrapper für Tor, also eine Software, die
eine andere Software umgibt, indem es die Torsocks mit einer bestimmten
Konfiguration aufruft. Mithilfe der Torsocks arbeitet Tor als Proxyserver,
mit dem man viele Internetanwendungen anonym benutzen kann, indem man ihnen
den Befehl torify voranstellt. Tor schickt dann deren Internetpakete
verschlüsselt über drei Server, auch Nodes genannt, und erst der letzte
Server, der Exit-Node, kann das Paket vollständig entschlüsseln und an den
eigentlichen Bestimmungsort weiterleiten. Der Server, für den die
Datenpakete bestimmt sind, sieht
dabei nur die IP des Exit-Nodes, und nicht die des Absenders.
Möchte man Tor mitteilen, dass eine neue Route durch das Netzwerk gesucht
werden soll, so wie man mit dem Tor-Button im Browser die Identität wechselt,
kann man mit folgendem Befehl eine neue Sitzung erstellen:
$ echo -e 'AUTHENTICATE \r\nSIGNAL NEWNYM\r\nQUIT' | nc localhost 9051
Mit dem Programm Netcat [7], auch nc
genannt, wird der Befehl SIGNAL NEWNYM
über eine Netzwerkverbindung zum Port (hier: 5091) des
Zielservers (hier: localhost) transportiert.
Jetzt wird ausgenutzt, dass
weiter oben die Zeile in der Konfigurationsdatei für diesen ControlPort
auskommentiert wurde: Tor lauscht also auf Befehle, die über diesen Port
hereinkommen. Der Befehl SIGNAL NEWNYM veranlasst Tor dazu, einen neuen Weg
durch sein Netzwerk zu suchen. Ob das geklappt hat, kann man schnell
feststellen, indem man seine IP-Adresse wieder mit torify überprüft:
$ torify wget -qO- ifconfig.me/ip
95.85.49.232
Wie man sieht, hat sich die IP-Adresse geändert. Anstelle von wget kann man
natürlich auch die IP-Adressen anderer Programme im Terminal verschleiern,
zum Beispiel die von SSH-Sitzungen, vom textbasiertem Webbrowser w3m, dem
IRC-Client BitchX, rTorrent oder cURL, um anonymisiert Dateien zu übertragen.
Passwort für Tor setzen
Wird der Rechner von mehreren Leuten benutzt oder Tor auf einem Server
betrieben, sollte man ein Passwort verwenden. Dazu wird zuerst ein
Passwort-Hash erstellt [8]:
$ tor --hash-password
"correcthorsebatterystaple"
[...]
16:8A043AE4F8D4343E602D71326A923F3524AD
549473D11FCD401A36F7EA
Die gekürzte Ausgabe zeigt nur die Zeile mit dem Hash, der in die
Konfigurationsdatei /etc/tor/torrc eingetragen werden muss. Nachdem diese
geöffnet wurde, muss der folgenden Zeile wieder ein Kommentarzeichen
vorangestellt werden, wie hier schon zu sehen ist:
#CookieAuthentication 0
Anschließend muss die Zeile für das Passwort auskommentiert und der Hash durch den soeben generierten ersetzt werden:
[LISTINGUMG_ALT]HashedControlPassword 16:8A043AE4F8D4343
E602D71326A923F3524AD549473D11FCD401A36F7EA
Nach dem Speichern der geänderten Konfigurationsdatei wird Tor wieder neu
gestartet:
# /etc/init.d/tor restart
Will man Tor jetzt mit SIGNAL NEWNYM mitteilen, dass ein anderer Weg durch
das Netzwerk genommen werden soll, muss man natürlich das Passwort
benutzen, um sich vorher zu authentifizieren, damit man das auch machen darf:
$ echo -e 'AUTHENTICATE
"correcthorsebatterystaple"[HTML-BACKSLASH]r[HTML-BACKSLASH]nSIGNAL
NEWNYM[HTML-BACKSLASH]r[HTML-BACKSLASH]nQUIT' - nc localhost 9051
Gefahren beim Benutzen von Tor
Auch im Terminal gelten dieselben Vorsichtsmaßnahmen, wie sie schon im
Artikel „Mit Tarnkappe im Netz: Das Tor Browser Bundle“ angesprochen wurden.
Tor schützt nicht vor der eigenen Dummheit. Wenn man seine Identität im
Internet preisgibt, hilft es nicht, wenn man vorher seine IP-Adresse
anonymisiert hat. Genauso sind auch bei Tor im Terminal „böse“ Exit-Nodes ein
Problem, weshalb man auch hier auf eine verschlüsselte Verbindung zwischen
dem eigenen Rechner und dem Zielsystem achten sollte.
Was dagegen Browser weniger trifft, aber Programme im Terminal, ist das
DNS-Leaking. DNS steht für Domain Name
System [9] und ist sozusagen
die Telefonauskunft des Internets. Ein Name, wie zum Beispiel
„freiesmagazin.de“ können sich Menschen leichter merken als die dazugehörige
„Anschlussnummer“, die IP-Adresse. Wenn der Domain-Name als URL ins Internet
geschickt wird, wandelt das Domain Name System sie in die dazugehörige
IP-Adresse um und leitet die Anfrage zum richtigen Server weiter.
Wenn das Chat-Programm, mit dem man sich anonym über das Tor-Netzwerk
unterhalten will, diese DNS-Anfrage aber mitsendet, kann ein Außenstehender
sehen, von wo aus man sich mit dem Chat-Server verbunden hat. Ob eine
Anwendung von diesem DNS-Leaking betroffen ist, kann man nur mit einem
Sniffer zur Analyse der Netzwerk-Kommunikation herausfinden, zum Beispiel
mit Wireshark [10]. Mit der
Kommandozeilen-Version tshark schneidet man dann sämtliche DNS-Anfragen mit,
die den eigenen Rechner verlassen. Anschließend startet man das
Programm, von dem man den Verdacht hat, dass es vom DNS-Leaking betroffen
ist [11].
Schließlich können auch Schwachstellen im Tor-Protokoll selbst ausgenutzt
werden. Inwieweit das schon geschieht, ist unklar, was aber auch in der
Natur der Sache beim Ausnutzen von Schwachstellen liegt. Hier bemüht sich
das Tor-Projekt aber um größtmögliche Transparenz. Es lohnt sich also, ein
Auge auf das Blog des Projekts zu haben [12].
Die Anonymisierung mit Tor hat schließlich
auch ihre Grenzen in der Menge
und der Verteilung der Nodes. Die Liste aller Tor-Knoten ist öffentlich.
Durch die Überwachung einer ausreichend großen Anzahl der Nodes oder auch
durch einen größeren Teil des Internets kann fast sämtliche Kommunikation
über Tor nachvollzogen werden. Geheimdienste können das erreichen, indem sie
Betreiber von Internet-Knoten oder wichtigen Backbones zur Kooperation
zwingen, da sich die Tor-Nodes auf nur wenige Länder verteilen. Es reicht
also die Zusammenarbeit von nur wenigen Instanzen, um die Anonymisierung im
Tor-Netzwerk deutlich zu schwächen. Dann müssen nur noch der erste und der
letzten Node überwacht werden, um durch eine statistische Auswertung auf den
Ursprung der Verbindung zu schließen.
Links
[1] http://www.freiesmagazin.de/freiesMagazin-2014-05
[2] https://de.wikipedia.org/wiki/Tor_(Netzwerk)
[3] http://wiki.ubuntuusers.de/Paketquellen#universe
[4] https://www.torproject.org/docs/debian
[5] https://www.torproject.org/docs/rpms.html.en
[6] https://www.torproject.org/docs/tor-doc-unix.html.en
[7] https://de.wikipedia.org/wiki/Netcat
[8] http://xkcd.com/936/
[9] https://de.wikipedia.org/wiki/Domain_Name_System
[10] http://wiki.ubuntuusers.de/Wireshark
[11] http://wiki.ubuntuusers.de/Tor/Gefahren
[12] https://blog.torproject.org/blog/
| Autoreninformation |
| Christian Imhorst (Webseite)
surft nur selten anonym im Internet. Wenn doch, dann benutzt er Tor, um die
Kontrolle über seine Privatsphäre so weit es geht zu behalten.
|
Beitrag teilen Beitrag kommentieren
Zum Index
von Sujeevan Vijayakumaran
Nutzer der Kommandozeile suchen häufig nach Suchmustern in Dateien. Das
gängigste Tool ist wohl grep [1]. Mit
ack [2] gibt es hingegen eine Alternative, die besonders
für Programmierer geeignet ist.
Ack ist komplett in Perl geschrieben und nutzt grundsätzlich den Funktionsumfang
der Regulären Ausdrücke von Perl. Der Schwerpunkt von ack liegt in der
Optimierung für Programmierer, denn ack beachtet standardmäßig schon
einige Dinge, um Verzeichnisse nicht unnötig zu durchsuchen.
Die Anwendung ack ist in den gängigen Paketquellen der Linux-Distributionen
enthalten. Unter Fedora oder ArchLinux heißt das Paket schlicht ack, in
Debian-basierten Distributionen hingegen ack-grep.
Ack nutzen
Ack sucht im Standard rekursiv. Als Nutzer muss man also kein „-r“ für
rekursives Suchen mit angeben, anders als z. B. bei grep. Die Funktionsweise von
ack wird hier anhand dieses
Repositories [3] deutlich gemacht.
Wenn man nun beispielsweise in einem Quellcode nach „Database“ suchen will,
reicht folgender Befehl:
$ ack Database
Der Befehl von grep sähe hingegen so aus:
$ grep -r Database
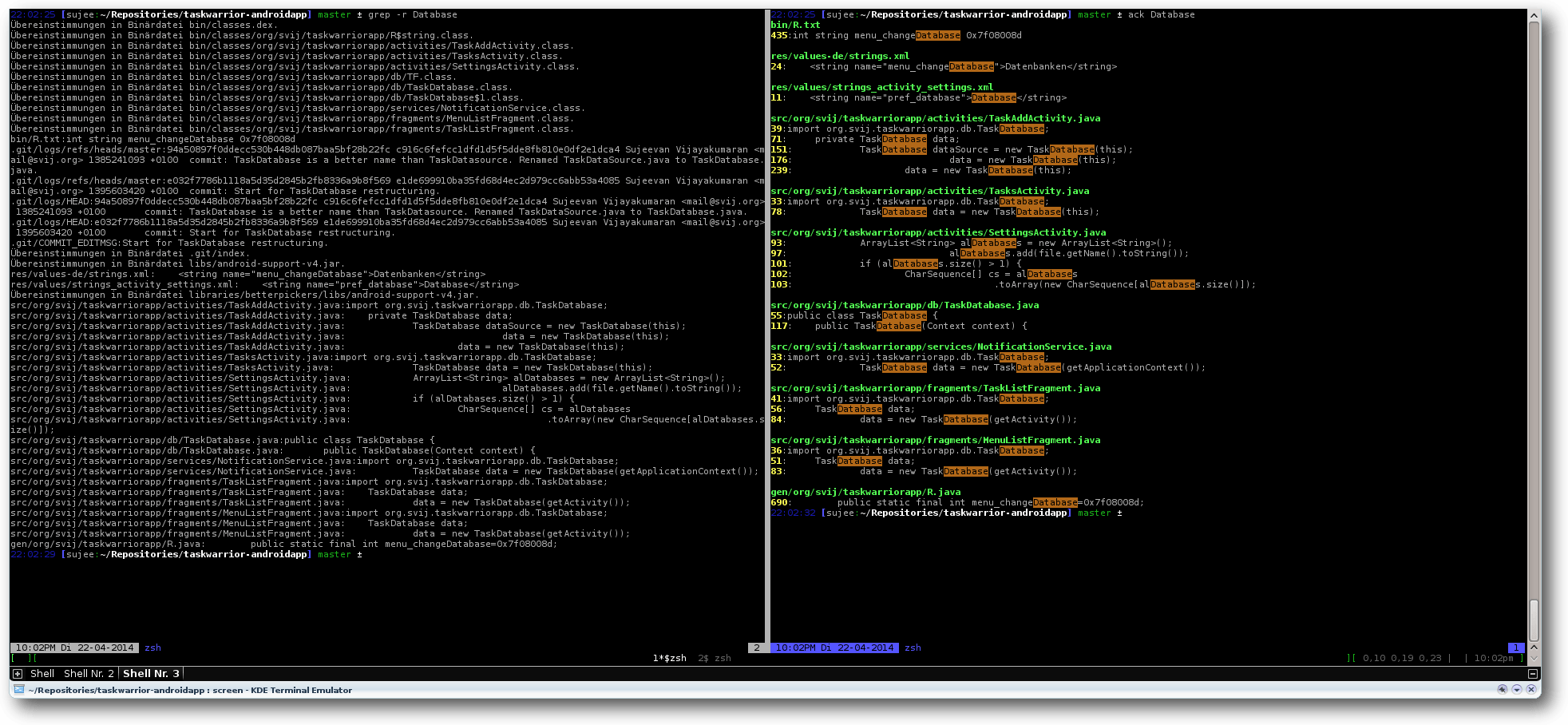
Suche nach „Database“ mit grep (links) und ack (rechts).
Ack sucht rekursiv nach dem String „Database“. Das Ergebnis wird dabei mit
Hilfe verschiedener Farben hervorgehoben. Sichtbar sind drei Dinge:
Dateiname, Zeilennummer sowie Zeileninhalt mit hervorgehobenem Suchbegriff.
Im Gegensatz zu grep ist die Standard-Ausgabe von ack deutlich besser lesbar.
Weiterhin dürfte einigen noch ein Detail auffallen: Bei der Suche mit grep
werden, im Gegensatz zur Suche mit ack,
Suchergebnisse auch aus dem „.git“-Unterverzeichnis gefunden.
Ack ignoriert Verzeichnisse von
Versionsverwaltungssystemen.
„.svn“-Verzeichnisse werden nicht durchsucht, da man schließlich in echten Dateien
suchen will und nicht in Repository-Dateien. ack durchsucht auch keine
Backup-Dateien, wie etwa „beispiel~“ oder Binärdateien. Die Macher von ack
möchten mit dieser Vorgehensweise unerwünschte Such-Treffer verhindern bzw.
ausblenden.
Mein Beispiel-Repository ist ein Android-Projekt, in dem nicht nur Java-Code
enthalten ist, sondern auch diverse XML-Dateien, einige Binärdateien und natürlich Java-Klassen,
die während der Entwicklung automatisch generiert werden. Mit ack ist es auch
sehr einfach möglich, bestimmte Suchbegriffe auf einzelne Programmiersprachen
zu beschränken.
Wenn man nun nach „Database“ nur in Java-Dateien suchen will, kann man einfach
$ ack --java Database
ausführen. Wenn man hingegen nur in XML-Dateien suchen möchte, nutzt man
folgenden Befehl:
$ ack --xml Database
Besonders in größeren Software-Projekten ist dies dann praktisch, wenn mehrere
Programmiersprachen zum Einsatz kommen. Die Dateityp-basierte Suche
lässt sich ebenfalls umdrehen, wenn man beispielsweise explizit nicht in
XML-Dateien suchen möchte.
$ ack --noxml Database
Ack nutzt in dieser Funktion nicht nur die Dateiendung der einzelnen Dateien,
sondern prüft auch die Shebang-Zeile [4],
so dass auch Dateien ohne Dateiendung, aber mit Shebang-Zeile
richtig erkannt und durchsucht werden.
Weiterhin unterstützt ack die altbekannten Kommandozeilen-Optionen von grep,
wie etwa „-i“ für case-insensitive Suchen oder „-v“ für eine invertierte Suche.
Ack besitzt noch zahlreiche weitere Optionen, die sich in der
Dokumentation [5]
nachlesen lassen. Programmierer dürften ack mit seinen Funktionen durchaus
einiges abgewinnen, da es schnell sucht und übersichtliche Ergebnisse liefert.
Nichtsdestoweniger ist und bleibt grep ein Tool, das man weiterhin nutzen
kann, da es schließlich auf jedem unixoiden Betriebssystem als Standard vorhanden
ist.
Links
[1] https://de.wikipedia.org/wiki/Grep
[2] http://beyondgrep.com/
[3] https://github.com/svijee/taskwarrior-androidapp
[4] https://de.wikipedia.org/wiki/Shebang
[5] http://beyondgrep.com/documentation/
| Autoreninformation |
| Sujeevan Vijayakumaran (Webseite)
stieß beim Lesen des Buches „Vim in der Praxis“ auf ack
und war überrascht, wie sehr ack das Suchen erleichtert.
|
Beitrag teilen Beitrag kommentieren
Zum Index
von Patrick Gundlach
Es gibt eine Reihe von Dokumenten, die sich nur schwer mit freier Software
erstellen lassen. Für normale Texte wie Bücher oder Abschlussarbeiten gibt
es LibreOffice [1] und
LaTeX [2], für Zeitschriftensatz (DTP) gibt
es beispielsweise Scribus [3]. Doch
vollautomatisch aus Datenbanken erzeugte Dokumente lassen sich oft nur
schwer mit den genannten Programmen erzeugen. Hier soll der „speedata
Publisher“ helfen, der in diesem Artikel vorgestellt wird.
Einleitung
TeX beziehungsweise LaTeX kann man zwar sehr gut automatisieren, doch man stößt doch recht schnell
an die Grenzen, wenn man zum Beispiel komplexe Tabellen oder automatisch
überlaufende Textcontainer benötigt. Auf der anderen Seite kann Programme wie Scribus zu automatisieren
eine Herausforderung sein. Im professionellen Umfeld wird hier häufig
InDesign von Adobe [4] benutzt.
Für InDesign gibt es eine große Anzahl proprietärer Plug-ins, die aus
Datenbanken mithilfe von Templates automatisiert Dokumente erzeugen können. Der bekannte
W3C-Standard XSL-FO [5] eignet sich sehr
gut für die vollautomatische Erstellung von Dokumenten, die
Dokumentbeschreibung (FO) ist jedoch in den Möglichkeiten stark
eingeschränkt. Außerdem sind die freien Implementierungen (zum Beispiel
Apache FOP [6]) leider derzeit nicht
für ihre gute Ausgabequalität berühmt.
Im Database Publishing geht es hauptsächlich um die Erzeugung von
Produktkatalogen, Preislisten, Datenblättern und ähnlichen Dokumenten. Die
Daten liegen üblicherweise in einer Datenbank oder in Excel-Tabellen vor.
JSON [7], CSV oder ähnliche einfache Formate
haben praktisch keine Bedeutung für Database Publishing. Auch wenn XML oft
als geschwätzig und unnötig kompliziert verspottet wird, ist es fast das
einzig akzeptierte Datenaustauschformat (insbesondere im professionellen
Umfeld). Daher wird im Database Publishing oft XML als Datenquelle
vorausgesetzt.
Als Ausgabe wird in der Regel PDF genommen, es kann aber auch (Stichwort:
Cross Media Publishing) etwas völlig anderes sein, wie z. B. die Befüllung von
Webshops oder Vorbereitung für Smartphone- und Tablet-Apps. Aber auch ePub
hat an Bedeutung gewonnen. In diesem Artikel geht es ausschließlich um die
Ausgabe in PDF. Vorgestellt wird die Software „speedata Publisher“, mit der
sich die genannten Dokumente leicht erstellen lassen.
Installation
Der speedata Publisher ist ein Kommandozeilenprogramm, das für Linux, Mac OS
X und Windows verfügbar ist und unter der freien
AGPL-Lizenz [8] steht. Die Quellen
sind auf Github verfügbar [9];
fertige Pakete zur Benutzung liegen auf der Webseite zum Download
bereit [10]. Es wird empfohlen,
für Experimente die aktuelle Entwicklungsversion (unstable) zu benutzen. Die
Installation ist einfach: das Paket liegt als ZIP-Datei vor und muss nur
entpackt werden. Optional kann die PATH-Umgebungsvariable auf das
Verzeichnis bin gesetzt werden. Alternativ dazu muss man (wie man es von
Unix her kennt) beim Programmaufruf den relativen oder absoluten Pfad
mitgeben.
Unter der Haube verwendet der Publisher LuaTeX [11],
eine moderne Variante des Textsatzsystems TeX, das für seine hochwertige
Ausgabe bekannt ist. Der Anwender kommt damit jedoch nicht in Berührung und
muss sich nicht mit den Eigenheiten von TeX auseinandersetzen. Die
ZIP-Pakete sind vollständig, das heißt es werden für den normalen Betrieb
keine weiteren Programme benötigt. Möchte man vor dem Durchlauf einen
XProc-Filter benutzen (z. B. für XSLT-Transformationen), wird eine Java
Runtime Environment benötigt. Wer nur Dokumente aus XML-Dateien erzeugen
möchte, braucht das jedoch nicht.
Hello world
Die Einführung in eine neue Programmiersprache geschieht meist mit einem
„Hello World“-Programm. Bevor aber das erste Dokument erzeugt werden kann,
gibt es eine kleine Erklärung zur Vorgehensweise beim Database Publishing
mit dem speedata Publisher. Der Publisher benötigt immer genau zwei Dateien
als Eingabe (abgesehen von Bildern und Schriftdateien, die in das Dokument
eingebunden werden): eine Datendatei und eine Layoutbeschreibung. Beide
Dateien müssen im XML-Format vorliegen. Die Datendatei kann beliebig
strukturiert werden. Es gibt also kein festes Schema für den Aufbau der
Datendatei. Der Dateiname für die Daten ist in der Voreinstellung
data.xml.
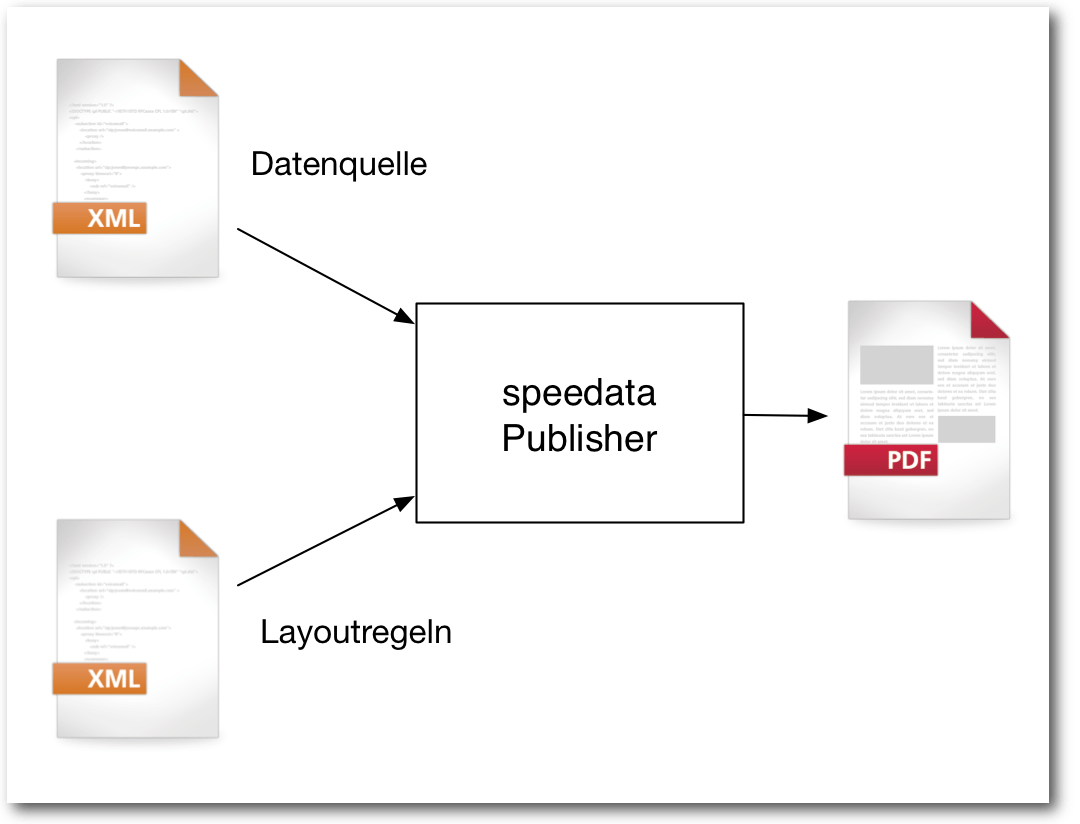
Daten und Layout bilden die Grundlage des speedata Publishers.
Für das einfache Beispiel reicht der folgende Inhalt:
<data>Hello world</data>
Listing: helloworld_data.xml
Die Layoutbeschreibung muss dabei einem vorgegebenen Schema folgen. Das Schema ist
als RelaxNG-Datei in der Distribution enthalten (im Unterverzeichnis
share/schema). Am besten bearbeitet man die Layoutbeschreibung (das
Regelwerk) mit einem XML-fähigen Editor wie zum Beispiel jEdit [12]
(siehe auch freiesMagazin
05/2014 [13]) zusammen mit dem
XML-Plug-in oder direkt mit einem spezialisieren Editor wie
Oxygen [14]. Bei beiden Editoren kann man das
Schema mit dem Dokument verbinden, sodass bei der Eingabe sowohl ein
Syntaxcheck als auch die Autovervollständigung und teilweise auch die Online-Hilfe
(Oxygen) verfügbar ist. Das Layoutregelwerk wird unter dem Namen
layout.xml gespeichert:
<Layout xmlns="urn:speedata.de:2009/publisher/en">
<Record element="data">
<PlaceObject>
<Textblock>
<Paragraph>
<Value select="string(.)" />
</Paragraph>
</Textblock>
</PlaceObject>
</Record>
</Layout>
Listing: helloworld_layout.xml
Neben der englischsprachigen Syntax gibt es auch eine deutschsprachige, auf
diese wird hier nicht weiter eingegangen. Hat man beide Dateien (data.xml
und layout.xml) in einem Verzeichnis erstellt, dann kann der Publisher
mit dem Befehl
$ sp
aufgerufen werden. Wenn man nicht die Standarddateinamen für die XML-Dateien
benutzt, kann man diese als Optionen mit angeben. Beispielsweise für die
„Hello world“-Dateien oben:
$ sp --data=helloworld_data.xml --layout=helloworld_layout.xml
Es wird dann eine PDF-Datei publisher.pdf erstellt, die
die Worte „Hello world“ enthält.
Die Anweisungen im Regelwerk setzen sich zusammen aus deklarativen Befehlen
(Farben festlegen, Schriftarten laden), strukturierenden Elementen (Zugriff
auf Daten, Programmierkonstrukte) und Ausgabeanweisungen (Bilder, Texte,
Tabellen, Barcodes u.ä.). Da es derzeit noch keinen Standard für diese Art
von Layoutbeschreibung gibt, orientiert sich das Regelwerk an HTML, XPath,
XSLT und CSS (alles W3C-Standards).
Datenstrukturierung und -zugriff
Da die Datenquelle beliebig strukturiert sein kann, gibt es verschiedene
Befehle, um aus dem Layoutregelwerk auf die Daten zuzugreifen. Wenn der
speedata Publisher startet, sucht er nach einem Einsprungspunkt für das
Wurzelelement in den Daten. In dem „Hello world“-Beispiel war das das Element
mit dem Namen data. Das Gegenstück in dem Regelwerk lautet
<Record element="data">
Sobald der Publisher auf ein Element in den Daten trifft, sucht er im
Layoutregelwerk den Befehl Record mit dem Attribut element, dessen
Inhalt der Name des Elements aus den Daten ist. Hat das Programm einen
passenden Befehl Record gefunden, werden alle Befehle innerhalb des
Elements ausgeführt.
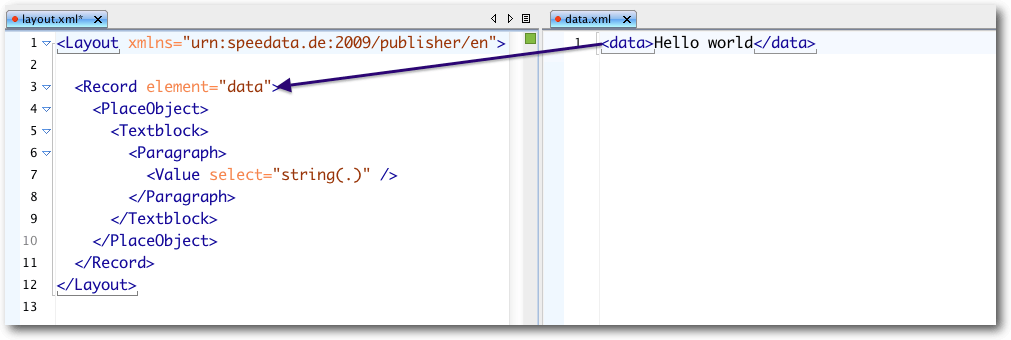
Zusammenhang zwischen Elementen in der Datendatei und der Verarbeitung im Layoutregelwerk.
In dem Beispiel ist das nur der Befehl PlaceObject, um ein Objekt zu
platzieren. Innerhalb eines Record-Befehls kann mit ProcessNode
auf Kindelemente in den Daten zugegriffen werden. Wenn beispielsweise
folgende Daten-XML vorliegen:
<configuration>
<os arch="i386, amd64">Linux</os>
<os arch="amd64">Mac OS X</os>
<os arch="i386, amd64">Windows</os>
</configuration>
Listing: datahandling_data.xml
kann im Layout auf die Inhalte wie folgt zugegriffen werden:
<Layout xmlns="urn:speedata.de:2009/publisher/en">
<Options mainlanguage="German"/>
<Record element="configuration">
<PlaceObject>
<Textblock>
<Paragraph>
<B>
<Value>Unterstützte Plattformen</Value>
</B>
</Paragraph>
</Textblock>
</PlaceObject>
<!-- Ruft für jedes Kindelement den passenden
<Record> auf -->
<ProcessNode select="os"/>
</Record>
<!-- wird durch <ProcessNode ... /> aufgerufen -->
<Record element="os">
<PlaceObject>
<Textblock>
<Paragraph>
<Value select="string(.)"/>
<I>
<Value> (</Value>
<Value select="@arch"/>
<Value>)</Value>
</I>
</Paragraph>
</Textblock>
</PlaceObject>
</Record>
</Layout>
Listing: datahandling_layout.xml
Der Befehl ProcessNode ruft den passenden Record für jedes Kindelement
mit diesem Namen auf. Beim Ausführen des Befehls Record element="os"
befindet sich der Publisher im Element os und man kann mit @... auf
Attribute und mit . auf den Inhalt des Elements zugreifen.
Alternativ und kürzer kann mithilfe des Befehls ForAll auf Kinddaten
zugegriffen werden (dieselben Daten, hier nur die Layoutdatei):
<Layout xmlns="urn:speedata.de:2009/publisher/en">
<Options mainlanguage="German"/>
<Record element="configuration">
<PlaceObject>
<Table padding="2pt" columndistance="4pt">
<Tr>
<Td>
<Paragraph>
<Value>Betriebssytem</Value>
</Paragraph>
</Td>
<Td>
<Paragraph>
<Value>Architektur</Value>
</Paragraph>
</Td>
</Tr>
<Tablerule/>
<ForAll select="os">
<Tr>
<Td>
<Paragraph>
<Value select="string(.)"/>
</Paragraph>
</Td>
<Td>
<Paragraph>
<Value select="@arch"/>
</Paragraph>
</Td>
</Tr>
</ForAll>
</Table>
</PlaceObject>
</Record>
</Layout>
Listing: datahandling2_layout.xml
Hier wird für jeden Eintrag os eine Tabellenzeile erzeugt. Der Fokus
(also der aktuelle Knoten im Daten-XML) ist nun abwechselnd in jedem der
Kindelemente, damit kann wie oben auf deren Inhalte zugegriffen werden.
Programmierkonstrukte
Die Layoutsprache enthält auch klassische Programmierkonstrukte wie
Variablen, Schleifen und Fallunterscheidungen. Schleifen lassen sich
beispielsweise so schreiben:
<SetVariable variable="i" select="4"/>
<While test="$i > 0">
<Message select="$i"/>
<SetVariable variable="i" select="$i - 1"/>
</While>
In dem Fall werden die Zahlen 4, 3, 2 und 1 in der Protokoll-Datei
ausgegeben. Bedingungen lassen sich mit Switch/Case/Otherwise
ausdrücken:
<Switch>
<Case test="count(*) = 0">
<Message select="'Keine Kindelemente'"/>
</Case>
<Case test="count(*) > 3">
<Message select="'Mehr als 3 Kindelemente'"/>
</Case>
<Otherwise>
<Message select="'Sonst'"/>
</Otherwise>
</Switch>
Mit diesen einfachen Bausteinen lassen sich Regelwerke erstellen, die auch
sehr komplexe Layoutvorgaben umsetzen können. Es gibt noch eine Reihe
weiterer Konstrukte, die sich im Handbuch (unter
share/doc/index-de.html) nachlesen lassen (z. B. Loop und Until).
Platzierung von Objekten im Raster
Als Grundlage für die Platzierung der Objekte dient ein Raster, das über die
Seite gelegt wird. Man kann bei der Erstellung der Seiten angeben, wie hoch
und wie breit eine Rasterzelle werden soll. Objekte werden, wie oben
gesehen, mit dem Befehl PlaceObject ausgegeben, dem man eine Angabe für
die Spalte und Zeile übergeben kann. Diese Angaben können entweder eine
absolute Maßeinheit sein (z. B. 20 mm), dann wird von der Ecke oben links
gemessen. Oder es ist eine Zahl, dann bezieht sie sich auf das Seitenraster,
wobei die obere linke Ecke die Koordinate (1,1) hat (innerhalb des
Seitenrands).
Alle Objekte, die man ausgibt, haben eine Breite und eine Höhe, gemessen in
Rasterzellen:
<PlaceObject row="2" column="3" valign="middle">
<Image file="duck.pdf" maxwidth="4" maxheight="4"/>
</PlaceObject>
Hier wird ein Bild mit der Breite und der Höhe 4 (Rasterzellen) in der
dritten Spalte und der zweiten Zeile ausgegeben. Die Zellen, in denen
Objekte platziert werden, markiert das System als „belegt“. Diese Zellen
können dann nicht erneut belegt werden. Gibt man keine Zeile und Spalte bei
PlaceObject an, so sucht sich das System passende Werte selbstständig. Dabei
gibt es einen Cursor, der an der Stelle bleibt, an der das letzte Objekt
ausgegeben wird. Das Seitenraster und die belegten Zellen kann man sich
anzeigen lassen, wenn man den Publisher mit den Optionen
$ sp --grid --show-gridallocation
aufruft oder stattdessen die entsprechen Optionen im Layoutregelwerk einschaltet (Befehl
Options).
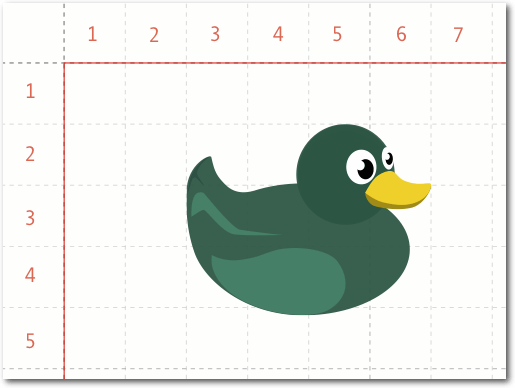
Seitenraster und Platzierung.
Seitenvorlagen
In einem Dokument sind selten alle Seiten gleicher Art. Es gibt Seiten, auf
denen keine Seitenzahl erscheinen soll, es gibt verschiedene Seitentypen mit
unterschiedlichen Kopf- und Fußzeilen oder manchmal müssen auch einfach nur die
Ränder für linke und rechte Seiten unterschiedlich sein.
Der speedata Publisher erlaubt dem Anwender, beliebige Seitenvorlagen zu
erstellen. Der Befehl dafür lautet Pagetype und sieht im einfachen Fall so
aus:
<Pagetype name="..." test="...">
<Margin left="2cm" right="1cm" top="1cm" bottom="2"/>
</Pagetype>
Das Attribut test erwartet einen XPath-Ausdruck der für jede Seite neu
evaluiert wird. Sobald eine Seitenvorlage gefunden wird, dessen
Test-Ausdruck den Wert „wahr“ ergibt, werden die Angaben aus dieser
Seitenvorlage übernommen.
Neben dem Rand kann man in der Vorlage auch Container definieren, die
automatisch überlaufen, wenn der Platz für den Inhalt nicht mehr ausreicht.
Ebenso lassen sich Befehle definieren, die ausgeführt werden, wenn eine
Seite mit diesem Seitentyp erzeugt oder ausgegeben wird. Das ist gut für
Kopf- und Fußzeilen geeignet.
<?xml version="1.0" encoding="UTF-8"?>
<Layout xmlns="urn:speedata.de:2009/publisher/en"
xmlns:sd="urn:speedata:2009/publisher/functions/en">
<Pagetype name="default" test="true()">
<Margin left="2cm" right="1cm" top="1cm" bottom="2" />
<AtPageCreation>
<Switch>
<Case test="sd:even(sd:current-page())">
<PlaceObject>
<Table stretch="max">
<!-- linke Seite -->
<Tr>
<Td>
<Paragraph>
<Value select="sd:current-page()" />
</Paragraph>
</Td>
<Td align="right">
<Image maxheight="1" file="logo.pdf" />
</Td>
</Tr>
<Tablerule />
</Table>
</PlaceObject>
</Case>
<Otherwise>
<!-- rechte Seite -->
<PlaceObject>
<Table stretch="max">
<Tr>
<Td align="left">
<Image maxheight="1" file="logo.pdf" />
</Td>
<Td align="right">
<Paragraph>
<Value select="sd:current-page()" />
</Paragraph>
</Td>
</Tr>
<Tablerule />
</Table>
</PlaceObject>
</Otherwise>
</Switch>
</AtPageCreation>
</Pagetype>
<Record element="data">
<PlaceObject>
<Textblock>
<Paragraph>
<Value>Eins</Value>
</Paragraph>
</Textblock>
</PlaceObject>
<NewPage />
<PlaceObject>
<Textblock>
<Paragraph>
<Value>Zwei</Value>
</Paragraph>
</Textblock>
</PlaceObject>
</Record>
</Layout>
Listing: kopffuss_layout.xml
<?xml version="1.0" encoding="UTF-8"?>
<Layout
xmlns="urn:speedata.de:2009/publisher/en"
xmlns:sd="urn:speedata:2009/publisher/functions/en">
<LoadFontfile name="Regular" filename="DejaVuSerif.ttf" />
<LoadFontfile name="Bold" filename="DejaVuSerif-Bold.ttf" />
<DefineFontfamily name="Überschrift" fontsize="14" leading="16">
<Regular fontface="Regular"/>
<Bold fontface="Bold"/>
</DefineFontfamily>
<Record element="data">
<PlaceObject>
<Textblock>
<Paragraph fontface="Überschrift">
<B><Value>Das ist eine fette Überschrift</Value></B>
</Paragraph>
</Textblock>
</PlaceObject>
</Record>
</Layout>
Listing: schriftarten_layout.xml
...
<LoadFontfile name="DejaVuSerif-Bold" filename="DejaVuSerif-Bold.ttf" />
<LoadFontfile name="DejaVuSerif" filename="DejaVuSerif.ttf" />
<LoadFontfile name="DejaVuSerifCondensed" filename="DejaVuSerifCondensed.ttf" />
...
Ausblick
Hier können nur wenige der zahlreichen Möglichkeiten des Publishers gezeigt
werden. Neben Kleinigkeiten wie Schnittmarken, automatischem Umfließen von
Bildern oder Setzen von PDF-Lesezeichen und Hyperlinks gibt es noch eine
Reihe weiterer Eigenschaften, die das System sehr mächtig machen. Es können
zur Laufzeit beliebige Daten gesammelt werden. Diese lassen sich sofort
verarbeiten, beispielsweise für einen Index. Oder man kann sie für den
nächsten Durchlauf des Publishers zwischenspeichern, sodass man dann auf die
Daten zugreifen kann, um beispielsweise Verzeichnisse zu erzeugen oder eine
Reihe von Optimierungen durchzuführen. Über diesen Mechanismus kann man z. B.
Bilder im Text verteilen, sodass der Platz auf einer Seite optimal genutzt
wird.
Die Software wird im kommerziellen Umfeld eingesetzt, daher ist ein
Schwerpunkt eine behutsame Weiterentwicklung. Es soll sichergestellt sein,
dass sich Neuentwicklungen nicht negativ auf bestehende Layoutregelwerke
auswirken. Dazu bietet sich die auf XML basierende Sprache sehr gut an.
Durch neue Elemente und Attribute kann Funktionalität hinzugefügt werden,
ohne dass bestehende geändert wird.
Eine Reihe automatisierter Tests stellt sicher, dass einmal
erstellte Layoutanweisungen immer dasselbe Ergebnis erzeugen. Diese Tests
funktionieren über einen optischen Vergleich einer Referenz-PDF mit einer
neu erstellten PDF-Datei. Dazu werden in einem ersten Schritt die
PDF-Dateien mittels Ghostscript nach PNG gewandelt und anschließend mit
ImageMagick [15] (Befehl compare) optisch
verglichen. ImageMagick erstellt eine Bilddatei mit den Unterschieden und
gibt auf der Standardausgabe einen Wert zurück, der den Unterschied als Zahl
ausdrückt.
Das mitgelieferte Handbuch (im Unterverzeichnis share/doc/ oder mittels
sp doc aufrufbar) enthält eine vollständige Beschreibung aller Befehle
mit Beispielen. Weiterhin sind auch einige einführende Kapitel enthalten,
z. B. zu Schnittmarken, der Einbindung von Schriftarten oder dem Erstellen eigener
Testfälle.
Zum Schluss darf der Hinweis nicht fehlen, dass die Entwicklung
für Vorschläge und Quellcode von außerhalb offen ist. Fast alle Eigenschaften des
Publishers stammen aus Anforderungen von Nutzern. Aber auch Fehlerberichte
oder kleine Korrekturvorschläge oder Beispiele durch Anwender sind immer
gerne gesehen.
Links
[1] http://de.libreoffice.org/
[2] http://www.latex-project.org/
[3] http://www.scribus.net/canvas/Scribus
[4] http://www.adobe.com/de/products/indesign.html
[5] https://de.wikipedia.org/wiki/XSL-FO
[6] http://xmlgraphics.apache.org/fop/
[7] https://de.wikipedia.org/wiki/JSON
[8] http://www.gnu.org/licenses/agpl-3.0.de.html
[9] https://github.com/speedata/publisher
[10] http://download.speedata.de/public/publisher/
[11] http://www.luatex.org/
[12] http://www.jedit.org/
[13] http://www.freiesmagazin.de/freiesMagazin-2014-05
[14] http://www.oxygenxml.com/
[15] http://www.imagemagick.org/
| Autoreninformation |
| Patrick Gundlach (Webseite)
ist Informatiker und interessiert sich seit langer Zeit für
Typographie und Textgestaltung. Als Gründer und Geschäftsführer der Firma
speedata macht er sein Hobby zum Beruf und entwickelt Software, die auch
kleinste typographische Details beherrscht.
|
Beitrag teilen Beitrag kommentieren
Zum Index
von Maria Seliger
Dieser Artikel beschäftigt sich mit Chat-, IRC- und Feedreader-Programmen sowie
mit Download-Managern. Aufgrund der Vielzahl der Programme wird nur ein kleiner
Teil vorgestellt.
Chat- und IRC-Programme
Unter Chat versteht man eine elektronische Kommunikation zwischen Personen
in Echtzeit. Diese findet oft über das Internet statt. Man unterscheidet
dabei unter anderem den textbasierten IRC-Chat (Internet Relay
Chat [1]) und Instant
Messaging. Beim IRC-Chat treffen sich Teilnehmer in einer Gesprächsrunde in
einem Channel. Dabei kann man an einem oder auch an mehreren Channeln teilnehmen.
Beim Instant Messaging unterhalten sich zwei oder mehr Teilnehmer per
Textnachrichten. Neben Textnachrichten werden oft auch Dateiübertragungen und
Videostreams unterstützt.
Empathy
Empathy [2] ist der
offizielle Instant-Messenger-Client des
GNOME-Projekts [3]. Es handelt sich dabei um einen
Multi-Protokoll-Client, mit dem sich sehr viele verschiedene Instant-Messenger-Dienste
nutzen lassen. Dazu zählen zum Beispiel ICQ, IRC, MSN, Jabber oder auch Yahoo! Messenger.
Empathy mit Kontakten und Kontextmenü.
Empathy unterstützt auch Video- und Audio-Chats über das XMPP-Protokoll.
Konfiguration der Messaging und Voice-over-IP-Accounts bei Empathy.
KDE Telepathy
KDE Telepathy [4] ist ein Instant
Messenger für KDE, der auf dem
Telepathy-Framework [5] basiert. KDE Telepathy
befindet sich zur Zeit noch in einem relativ jungem Stadium und soll der
Nachfolger des älteren Instant Messenger Kopete werden.
KDE Telepathy mit Kontakten und Kontextmenü.
Ähnlich wie Empathy unterstützt das Programm eine Vielzahl von Protokollen
und ermöglicht es, mehrere Instant-Messaging-Dienste wie zum Beispiel
XMPP (Jabber) oder
auch ICQ gleichzeitig zu verwenden.
Instant Messaging Konfiguration in KDE Telepathy.
Pidgin
Bei Pidgin [6] handelt es sich ebenfalls um einen freien
Multi-Protokoll-Client. So unterstützt das Programm unter anderem Bonjour, ICQ, IRC,
MSN, Yahoo! Messenger und XMPP (Jabber) sowie eine ganze Reihe weiterer Protokolle. Wie auch
Empathy und KDE Telepathy unterstützt Pidgin neben den normalen Textnachrichten auch Video- und Audio-Chats
über das XMPP-Protokoll.
Pidgin mit Kontakten und Kontextmenü.
Einige zusätzliche Protokolle werden über Plug-ins aktiviert, die für das
Programm geschrieben wurden (z. B. für Skype). Auch eine Verschlüsselung kann
über das Plug-in pidgin-encryption aktiviert werden. Insgesamt gibt es
über 100 Plug-ins, mit denen sich das Programm erweitern lässt.
Plug-in-Konfiguration für Pidgin.
- Homepage: https://www.pidgin.im/
- Lizenz: GPL
- Unterstützte Betriebssysteme: BSD, Linux, Windows. Für Windows gibt es auch eine portable Version.
Feedreader (RSS-Reader)
RSS-Reader sind Computerprogramme, mit denen sich Newsfeeds einlesen und
anzeigen lassen. Newsfeeds informieren über die Neuigkeiten auf einer Webseite.
Die Besonderheit dabei ist, dass eine Seite die Feeds selbst in die Welt streut und jeder
dieser abgreifen kann, wenn er denn Interesse daran hat. Dem Feed-Anbieter sind
die Empfänger seines Feeds somit also nicht direkt bekannt.
Akregator
Akregator [7] ist ein Feedreader für RSS-
und Atom-Feeds für KDE und Teil vom Personal Information Manager Kontact.
Das Programm kann aber auch eigenständig benutzt werden. Zu den Funktionen
zählen u. a.
- Text- und HTML-Ansicht der Feeds
- Organisation der Feeds in Ordnern
- Archivieren von Nachrichten
- Suchfunktionen
- Feednachrichten als wichtig kennzeichnen
Zur Ansicht der Nachrichten kann auch ein externer Webbrowser aufgerufen
werden.
Akregator
QuiteRSS
QuiteRSS [9] ist ein Feedreader mit einer grafischen
Oberfläche, mit der sich sehr gut verschiedene Newsfeeds verwalten lassen. Zu
den Funktionen zählen u. a.
- nur aktuelle Nachrichten anzeigen
- ältere Feeds automatisch löschen
- Feeds lassen sich in Ordner einordnen
- Feed-Nachrichten mit Tags (Labeln) kennzeichnen (z. B. wichtig, ToDo),
dabei können auch eigene Bezeichnungen vergeben werden
- Feed-Nachrichten mit anderen teilen (z. B. per E-Mail, Evernote, Twitter)
- Benachrichtigung per Sound oder Pop-Up
Durch den integrierten Webbrowser können die Nachrichten auch vollständig in
QuiteRSS angezeigt werden, sodass man keinen zusätzlichen Webbrowser
aufrufen muss.
QuiteRSS.
- Homepage: http://quiterss.org/
- Lizenz: GPL
- Unterstützte Betriebssysteme: Linux, MacOS X (Testphase), OS/2, Windows
Weitere Feedreader
Viele E-Mail-Programme, z. B. Mozilla Thunderbird, SeaMonkey oder
Sylpheed-Claws sowie Webbrowser z. B. Qupzilla bieten die Möglichkeit,
Newsfeeds zu lesen und zu verwalten. Zusätzliche gibt es z. B. für Firefox
diverse Add-ons, die die Newsfeed-Verwaltung ermöglichen (z. B. Newsfox, Sage).
Download-Manager und Dateitransfer
cURL (Client for URLs)
Das Kommandozeilen-Programm cURL [10] ist ein
Dateitransfer-Programm, das eine Vielzahl von Protokollen unterstützt
(DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3,
POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET, TFTP). Mit cURL
lassen sich Dateien z. B. aus dem Internet nicht nur herunterladen, cURL
ermöglicht auch das Hochladen von Dateien. Über zahlreiche
Kommandozeilenparameter lässt sich cURL konfigurieren. Diese lassen sich in
der Hilfe nachlesen.
Hilfe-Seite für cURL.
- Homepage: http://curl.haxx.se/
- Lizenz: MIT-Lizenz
- Unterstütze Betriebssysteme: BSD, Linux, MacOS X, OS/2, Windows
- Alternative: Wget Download-Manager (siehe unten)
FileZilla
FileZilla [11] dient der Dateiübertragung
mittels FTP, FTPS (FTP über SSL/TSL) und SFTP (SSH File Transfer Protocol).
FileZilla besteht aus mehreren Programmen, dem FileZilla Client und dem
FileZilla Server. Letzterer stellt einen FTP-Server bereit – hier geht es
aber um den Client.
Der Client stellt eine grafische Oberfläche bereit, um sich mit einem
FTP-Server zu verbinden. Dabei unterstützt das Programm auch IP-Version
6 [12]. FileZilla unterstützt außerdem auch die
Wiederaufnahme abgebrochener Datentransfers, die Verwaltung verschiedener
FTP-Sites sowie Drag&Drop.
FileZilla.
- Homepage: https://filezilla-project.org/
- Lizenz: GPL; bei Installation unter Windows ist es möglich, dass der
Installer Werbesoftware zu installieren versucht
- Unterstützte Betriebssysteme: Linux, MacOS X, Windows (auch portabel)
- Alternativen: Nautilus-Dateimanager unter GNOME, ftp als textbasiertes Programm für die Kommandozeile, FireFTP [13] als kostenloses Add-on für den Firefox-Browser
Transmission
Transmission [14] ist ein Client für das
BitTorrent-Filesharing-Protokoll [15].
Bei BitTorrent handelt es sich um ein kollaboratives Filesharing-Protokoll.
Es eignet sich insbesondere für die schnelle Verteilung großer Datenmengen,
da die Daten von mehreren Leuten parallel geladen werden.
Transmission ist für Ubuntu das Standardprogramm für das
BitTorrent-Netzwerk. Das
Programm ist sehr einfach zu bedienen. Zu den Funktionen von Transmission
zählen unter anderem das automatische Port-Mapping, die schnelle Wiederaufnahme von
angefangenen Übertragungen, eine individuelle Geschwindigkeitsbegrenzung für Torrents sowie
ein Priosierungssystem. Außerdem verfügt das Programm über ein optionales
Webfrontend.
Netzwerk-Einstellungen für Transmission.
- Homepage: http://www.transmissionbt.com/
- Lizenz: GPL
- Unterstützte Betriebssysteme: Linux, MacOS X, viele Embedded Systeme
- Alternativen: transmission-cli (Kommandozeile), transmission-daemon (Dienst)
Wget
Wget [16] ist ein Kommandozeilenprogramm
als Teil des GNU-Projekts. Das Programm ermöglicht das Herunterladen von
Dateien aus dem Internet und das Kopieren kompletter Webseiten, z. B. zum
Archivieren. Dabei bleibt auch die Struktur der Ordner erhalten. Die
Protokolle FTP, HTTP und HTTPS werden von Wget unterstützt.
Wget wird über zahlreiche Kommandozeilenparameter konfiguriert und bietet
eine ausführliche Hilfe an.
Hilfe-Seite für Wget.
- Homepage: https://www.gnu.org/software/wget/
- Lizenz: GPL
- Unterstützte Betriebssysteme: BSD, Linux, MacOS X, OS/2, Windows
- Alternative: cURL Down- und Upload-Manager (siehe oben)
Hinweis: Wget und cURL lassen sich auch einfach über das kostenlose Add-on
cliget [17] in den
Firefox-Browser einbinden.
Links
[1] https://de.wikipedia.org/wiki/Internet_Relay_Chat
[2] https://wiki.gnome.org/action/show/Apps/Empathy
[3] http://www.gnome.org/
[4] http://userbase.kde.org/Telepathy
[5] https://de.wikipedia.org/wiki/Telepathy
[6] https://www.pidgin.im/
[7] http://userbase.kde.org/Akregator
[8] http://lzone.de/liferea/
[9] http://quiterss.org/
[10] http://curl.haxx.se/
[11] https://filezilla-project.org/
[12] https://de.wikipedia.org/wiki/IPv6
[13] http://fireftp.mozdev.org/
[14] http://www.transmissionbt.com/
[15] https://de.wikipedia.org/wiki/BitTorrent
[16] https://www.gnu.org/software/wget/
[17] https://addons.mozilla.org/de/firefox/addon/cliget/
| Autoreninformation |
| Maria Seliger (Webseite)
ist vor über einem Jahr von Windows 7 auf Lubuntu umgestiegen, was problemlos ging, da sich für viele Programme
eine Alternative unter Linux fand.
|
Beitrag teilen Beitrag kommentieren
Zum Index
von Dominik Wagenführ
Die folgenden Tagebucheinträge wurden nach der Entlassung des Genossen
XXXXXXX in seiner Wohnung in der XXXXXXXX-Straße beschlagnahmt. Alle
persönlichen Daten wurden geschwärzt.
Tagebucheinträge
22. November 1982
„Heute ist mein Glückstag! Ich erhielt heute ein Schreiben, dass ich die
Arbeitslotterie des Monats gewonnen habe. Ich hatte mich zuerst gewundert,
weil ich an keiner Lotterie teilgenommen habe. Aber da man nicht jeden Tag
etwas gewinnt, habe ich mich trotzdem gefreut.“
„Der Gewinn ist eine neue Arbeitsstelle in Grestin. Unsere großartige
Führung in Arstotzka will die Grenzen nach Kolechien öffnen und jemand
muss natürlich die ehrenvolle Aufgabe übernehmen, die Einreisenden zu
kontrollieren.
Ich freue mich wahnsinnig, dass ich diese Aufgabe übernehmen
darf.“
„Meine Frau XXXXXX und mein Sohn XXXXX ziehen gleich mit in die
neue Wohnung ein. Auf die Mitnahme meiner Schwiegermutter hätte ich
verzichten können. Auch wenn mir unsere aktuelle Wohnung der Klasse 6
in XXXXXX gefällt, wird die neue der Klasse 8 in Ost-Grestin
sicher nicht schlecht sein.“

„In der Zeitung steht mein neuer Job.”
23. November 1982
„Mein erster Arbeitstag bei der Grenzstelle. Ich musste mich am Anfang durch
das Handbuch wühlen, aber prinzipiell sind die Regeln
einfach: Arstotzkaner
mit gültigem Pass dürfen rein, der Rest nicht. Immerhin zwölf Leute konnte
ich so abfertigen. Ich fand es etwas schade, dass nicht jeder in unser
schönes Arstotzka einreisen darf, aber das hat sicherlich seine Gründe.“
„Meine Grenzkabine ist gemütlich, aber nicht sehr groß. Vor allem
der Lautsprecher, mit dem ich ‚Es lebe Arstotzka!‘ und ‚Nächster!‘ in die
Menge brüllen darf, macht mir viel Freude.“

„Es lebe Arstotzka.“
24. November 1982
„Heute ist etwas Tragisches passiert. Es steht sicherlich morgen in allen
Zeitungen. Ein Terrorist ist bei der Einreise einfach über die Absperrung
gesprungen und hat eine Rohrbombe auf einen Grenzsoldaten geworfen. Es war
grauenhaft …“
„Und das auch noch an dem Tag, an dem unsere großartige Regierung die
Einreisebestimmungen gelockert hat. Eigentlich durfte jeder mit gültigem
Pass einreisen. Ich denke, das wird sich ab morgen ändern.“
25. November 1982
„Wie erwartet sind die Prüfungen jetzt wesentlich strenger – was für mich
mehr Arbeit bedeutet.
Es gab viele neue Regeln, die ich beachten muss.
Jeder Ausländer muss einen Einreisebeleg vorlegen, dessen Datum ich prüfen
muss.“
„Insgesamt gefällt mir die Arbeit gut. Es ist nicht so
anspruchsvoll, aber man sieht viele Menschen.“
26. November 1982
„Hätte ich mich gestern nur nicht beschwert. Einreisebelege sind wegen des
blühenden Schwarzmarktes nicht mehr erlaubt und ich muss jetzt
Einreise-Genehmigungen prüfen. Name, Passnummer und Einreisegrund müssen
alle geprüft werden und stimmen. Immerhin komme ich so mit den Leuten etwas
ins Gespräch, es ist aber dennoch anstrengend.“
„Vor allem bin ich durch die vielen Prüfungen nicht mehr so schnell. Gerade
einmal sechs Personen
konnte ich kontrollieren. Aber ich will keinen Fehler
machen. Da ich nur fünf Krediteinheiten pro Kontrolle bekomme, reicht das
Geld gerade einmal für Miete (die heute auch noch erhöht wurde) und Heizung.
Immerhin hatte ich etwas Geld gespart, um Essen für meine Familie kaufen zu
können.“
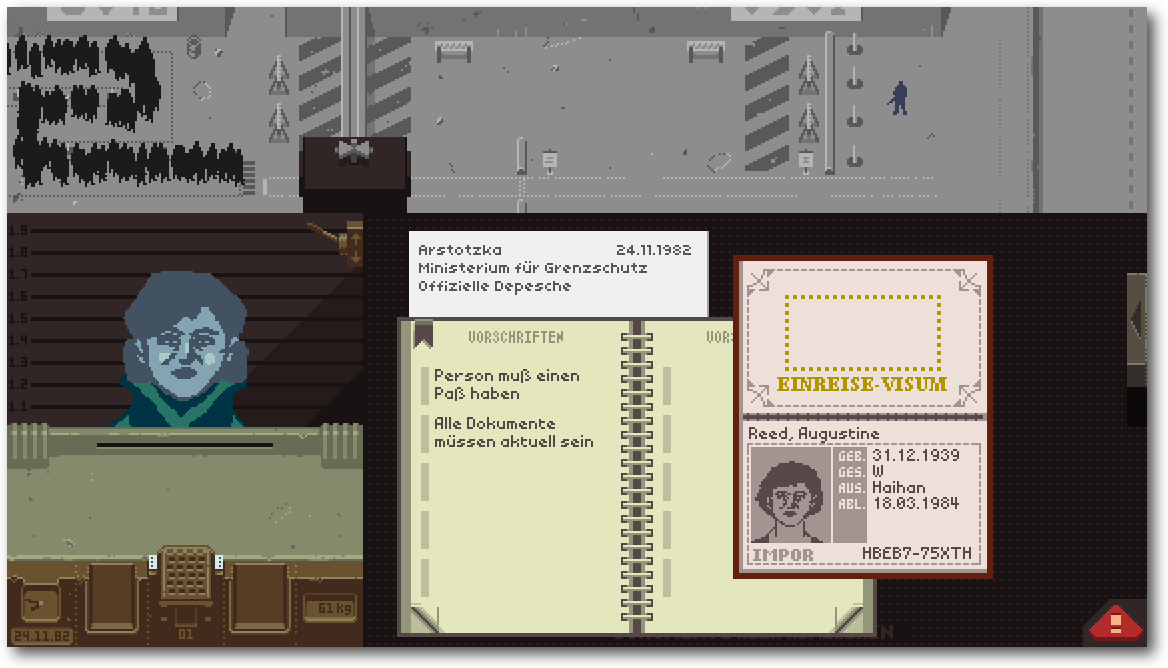
„Als Grenzschützer muss ich jeden Pass genau kontrollieren.“
27. November 1982
„Da es gestern so langsam voran ging, wollte ich heute etwas schneller
arbeiten. Die Ersparnisse halten nicht ewig als Reserve. Dummerweise sind
mir dabei mehrere Fehler passiert. Ich habe einige Leute wohl
fälschlicherweise weggeschickt, obwohl sie einreiseberechtigt waren.
Und ein oder zwei sind wohl durch meine Kontrolle geschlüpft, obwohl ihre Daten
nicht gepasst haben.“
„Jede meiner Entscheidungen wird wohl von höherer Ebene noch einmal geprüft,
wie auch immer die das machen. Jedenfalls gab es erst zwei Ermahnungen und
danach durfte ich fünf Krediteinheiten Bußgeld pro Fehler bezahlen. Im
Endeffekt habe ich heute nichts verdient, was ich meiner Frau natürlich
nicht sagen kann.“
„Die Ersparnisse reichen leider nicht mehr für Heizung und Essen. Ich hoffe,
dass mir meine Familie es abnimmt, dass bei Bauarbeiten was an den
Heizungsrohren kaputt gemacht wurde.“
28. November 1982
„Heute war ein schlimmer Tag. Das Ministerium hat mir einen Arrest-Knopf in
die Kabine eingebaut. Jedes Mal, wenn ich jemand Verdächtigen bemerke, soll
ich den drücken. Ich dachte mir nichts dabei und als ich ihn drückte, ging
ein Alarm los und zwei Wachen führten den Mann vor mir weg. Ich will gar
nicht wissen, was sie jetzt mit ihm machen.“
„Zusätzlich ist meine ganze Familie krank, weil es hier so saukalt ist. Ich
habe heute wieder nicht genug Geld nach Hause gebracht, um Miete, Heizung
und Essen zu bezahlen. Zusätzlich brauchte
ich auch noch Medikamente für
XXXXXXX und XXXXXXX. Ich glaube, wir müssen, das Essen rationieren.“
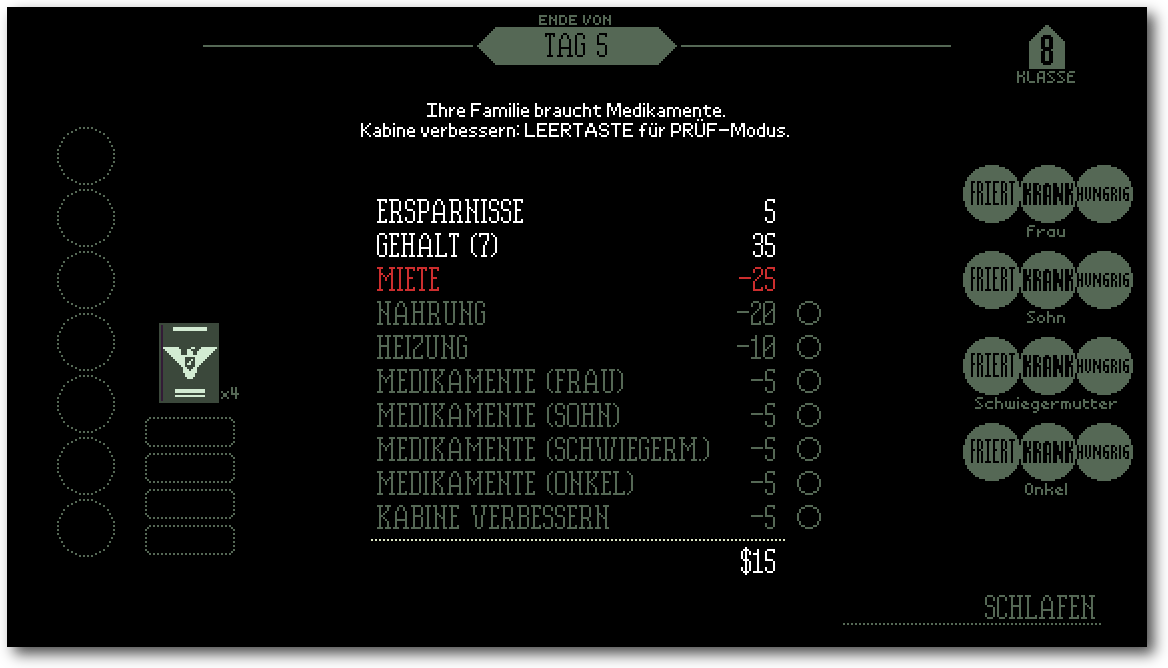
„Entweder Essen oder Medikamente für die Familie …“
29. November 1982
„Ich kann nicht mehr! Drei weitere Leute mussten wegen mir abgeführt werden.
Ich hätte sie ja gerne durchgelassen, denn sie sahen echt nicht wie
Terroristen aus. Aber ich hatte davor schon zwei Fehler gemacht und jeder
weitere hätte wieder negative Krediteinheiten bedeutet.“
„XXXXXXX ist wieder gesund, aber XXXXXXX hat den Tag nicht überlebt. Ich
weiß, man sollte das nicht sagen, aber ich konnte sie eh nie leiden. Ich
versuche natürlich dennoch XXXXXXX zu trösten, aber mir scheint, sie gibt
mir die Schuld daran.“
30. November 1982
„Als ich heute nach Hause kam, lag ein Brief vom Ministerium auf dem Tisch.
Weil wegen mir ein Familienmitglied gestorben ist und die Partei nur
erfolgreiche Mitarbeiter in ihren Reihen wissen will, wurde ich entlassen.
Die Wohnung wurde uns gekündigt. Morgen werde ich mich an den Grenzübergang
nach Kolechien stellen. Hoffentlich sind deren Auflagen für eine Einreise
nicht so streng wie bei uns …“
Zahlen und Fakten
„Papers, Please“ [1] ist ein sehr ungewöhnliches
Spiel. Der Startbildschirm und die militärische Musik zeigen es deutlich,
dass man kein Highend-Grafik-Spiel erwarten kann. Dafür überzeugt „Papers,
Please“ durch moralische Entscheidungen, die dem eigentlichen Spielziel,
Fehler in einem Suchbild zu finden, oft entgegenlaufen.

Titelbildschirm von „Papers, Please“.
Das macht das Spiel dann auch aus, denn man muss schon zweimal überlegen, ob
man immer nach Vorschrift arbeitet oder eine Familie, die den Grenzübergang
passieren will, trennt, weil bei einer Person der Pass abgelaufen ist.
Teilweise haben Entscheidungen sogar Auswirkungen, die in der Zeitung am
nächsten Tag aufgegriffen werden.
Durch die Bestrafung von Fehlern überlegt man sich auch zweimal, ob man
absichtlich jemanden die Grenze überqueren lässt, der eigentlich nicht
dürfte. Grob gerechnet muss man jeden Tag mindestens zwölf Personen korrekt
kontrollieren, damit man Miete, Heizung und Essen bezahlen kann. Reicht das
Geld nicht aus, muss man entweder Heizung oder Nahrung streichen, was sich
auf die Gesundheit der Familienmitglieder auswirkt. Eine wissentliche
Fehlentscheidung kann sich also auf die eigene Familie auswirken.
Leider kann man deswegen auch nicht einfach die Regeln des Spiels über den
Haufen werfen, in dem man einfach alle Menschen einreisen lässt, was bei
freien Grenzen ja toll wäre. Das System bestraft einen so stark, dass man so
keine zwei Tage weit kommt.
„Papers, Please“ selbst kann man beispielsweise über
Steam [2] oder den Humble
Store [3]
erstehen. Der Preis liegt bei ca. 9 US-Dollar. Das Spiel liegt in
verschiedenen Sprachen vor, unter anderem auch Deutsch.
Links
[1] http://papersplea.se/
[2] http://store.steampowered.com/app/239030
[3] https://www.humblebundle.com/store/p/papersplease_storefront
| Autoreninformation |
| Dominik Wagenführ (Webseite)
spielt gerne unter Linux und fand die moralischen Entscheidungen in
„Papers, Please“ sehr interessant.
|
Beitrag teilen Beitrag kommentieren
Zum Index
von Sujeevan Vijayakumaran
Das Buch „Vim in der Praxis“ vom Autor Drew Neil erschien Ende Dezember in der
ersten Auflage und bündelt auf über 300 Seiten eine große Anzahl an Tipps und
Tricks für die Nutzung von Vim.
Redaktioneller Hinweis: Wir danken O'Reilly für die Bereitstellung eines Rezensionsexemplares.
Was steht drin?
Das Buch umfasst insgesamt 121 Vim-Tipps, verteilt auf 21 Kapitel und abgedruckt auf
353 Seiten. Es wurde vom Autor Drew Neil ursprünglich auf Englisch für den
Verlag „Pragmatic Bookshelf“ verfasst. Die deutsche Übersetzung erfolgte durch
Lars Schulten für den O'Reilly Verlag.
Zusätzlich zu den 21 Kapiteln ist das Buch zudem in sechs einzelne Teile
gegliedert. Diese teilen das Buch sinnvoll in verschiedene Aspekte, die für
die Nutzung von Vim nützlich sind: „Modi“, „Dateien“,
„Rascher vorankommen“, „Register“, „Makros“, „Muster“ und „Werkzeuge“.
Das Buch beginnt mit „Lies mich“ und „Das vergessene Handbuch“. Beides sollte
man definitiv lesen, sofern man sinnvoll mit dem Buch arbeiten möchte.
Im „Lies mich“ wird der Aufbau des Buches erläutert, während „Das vergessene
Handbuch“ auf die Notationen und Formen des Buches eingeht, damit man sämtliche
Tastendrücke, die im Buch erwähnt werden, nachvollziehen kann.
Das Buch ist nicht als klassisches Lehrbuch aufgebaut, welches man von vorne
nach hinten durcharbeiten kann bzw. soll. Stattdessen wird bereits zu Beginn
ausdrücklich empfohlen, das Buch quer durchzublättern und nach und nach einige
der vielen Tipps auszuprobieren und nachzuvollziehen.
Im ersten Teil beschreibt der Autor die Funktionsweise der einzelnen Modi von
Vim. Er nennt und erläutert die folgenden fünf Modi anhand von zahlreichen Beispielen:
„Normaler Modus“, „Einfügemodus“, „Visueller Modus“ sowie „Kommandozeilenmodus“.
Im zweiten Teil geht es grundsätzlich um die Handhabung von Dateien, etwa wie
man Dateien öffnet, speichert oder generell mehrere Dateien gleichzeitig
verwaltet. Im Anschluss folgt der dritte Teil, der die Bewegungen innerhalb von
Dateien erläutert. Besonders dieser Teil sollte von Einsteigern zuerst gelesen
und verstanden werden, da die Bewegung innerhalb von Vim eines der essentiellen
Dinge ist, um Vim nutzen zu können.
Der vierte Teil dreht sich um Register, also wie man Texte kopiert, einfügt und
wie man mit Makros arbeitet. Im Anschluss folgt der nächste Teil über Muster.
Dort wird unter anderem erklärt, wie man schnell und effizient sucht, findet und
ersetzt. Der letzte und sechste Teil bespricht vorhandene Werkzeuge, die Vim
sinnvoll ergänzt. So wird unter anderem erklärt, wie man Code mit Make kompilieren
kann, eine automatische Vervollständigung aktiviert oder wie man
die Rechtschreibprüfung von Vim aktiviert und nutzt.
Wie liest es sich?
Das Buch setzt grundsätzlich keinerlei Kenntnisse in Vim voraus.
Nichtsdestoweniger dürften sich Vim-Anfänger anfänglich mit dem Buch schwertun,
da vor allem die Bedienung von Vim zu Beginn ungewohnt ist. Leser, die vorher
mindestens den "vimtutor" durchgearbeitet haben, werden hiermit allerdings
weniger Probleme haben.
Die Tipps in dem Buch lesen sich grundsätzlich ziemlich gut und sind so gut
wie immer sehr gut verständlich. Die angeführten Beispiele lassen sich leicht
nachvollziehen und verstehen. Häufig muss man allerdings die Notation der Beispiele
im Kapitel „Lies mich“ nachblättern.
Die Tipps behandeln nicht nur die grundsätzlichen Vim-Features, sondern gehen
auch sehr tief in einige Funktionen ein. Nur wenige Funktionen, die angesprochen
werden, werden oberflächlich angekratzt, denn meistens wird ausführlich
erläutert, was mit welchem Kommando möglich ist und auch wie man es möglicherweise
optimieren kann.
Nachdem man das Buch einmal durchgearbeitet hat, vergisst man leider sehr schnell
viele der Tipps. Das Buch eignet sich zudem besonders als Handbuch, welches man
dann zu Rate ziehen kann, wenn man es gerade braucht, denn merken kann man sich
alle Tipps nach dem ersten Ausprobieren leider nicht.
Kritik
Vim-Anfänger werden mit diesem Buch Vim lieben lernen. Es macht viel Spaß, die
einzelnen Tipps durchzuarbeiten und dabei einiges auszuprobieren. Sobald man
erst einmal angefangen hat, bleibt man häufig gut dabei und probiert weitere
Tipps und Tricks. Für den Leser wird dabei auch deutlich, wie viele Möglichkeiten
Vim so bietet und wie man sie auch in der Praxis sinnvoll einsetzen kann.
Der einzige echte Kritikpunkt ist lediglich der Preis. Mit 35 € ist es
wahrlich kein Schnäppchen für ein Buch, welches ohne farbige Seiten daherkommt.
So gibt es viele Fachbücher, die zwar ausführlicher sind; allerdings kann
man diesem Buch wenigstens auf fast jeder Seite etwas neues abgewinnen, sofern
man noch kein Vim-Profi ist. Wer sich also sinnvoll mit Vim auseinandersetzen
will, der findet mit diesem Buch eine sehr gute Grundlage um Vim zu erlernen.
| Buchinformationen |
| Titel | Vim in der Praxis [1] |
| Autor | Drew Neil, Übersetzung von Lars Schulten |
| Verlag | O'Reilly, 2013 |
| Umfang | 353 Seiten |
| ISBN | 978-3-95561-578-9 |
| Preis | 34,90 € (Print), 28,00 € (eBook)
|
Links
[1] http://www.oreilly.de/catalog/practicalvimger/
| Autoreninformation |
| Sujeevan Vijayakumaran
nutzte bisher Vim häufig nur, um Kleinigkeiten innerhalb von Textdateien
anzupassen. Nach dem Buch war er noch begeisterter von Vim als zuvor.
|
Beitrag teilen Beitrag kommentieren
Zum Index
von Christina Möller
Spätestens wenn die Abschlussarbeit für die Studierenden bevorsteht, stellt
sich die Frage, ob es Alternativen zu Microsoft
Word [1] gibt. Einen einfachen Einstieg
für diejenigen, die einen Umstieg nach LaTeX in Erwägung ziehen, bietet das
Buch „Wissenschaftliche Arbeiten schreiben mit LaTeX“ von Joachim Schlosser.
Redaktioneller Hinweis: Wir danken dem mitp-Verlag für die Bereitstellung eines Rezensionsexemplares.
Inhalt
Das Buch setzt sich aus den drei großen Bereichen „Einführung“,
„LaTeX-Elemente“ und „Fertigstellen der Arbeit“ zusammen.
Im ersten Teil wird nach den allgemeinen Informationen zu LaTeX die
Installation beschrieben. Zum Abschluss werden anhand eines einfachen
Beispiels die wesentlichen Bestandteile eines LaTeX-Dokuments vorgestellt.
Ausgestattet mit einem Grundgerüst geht es im zweiten Teil des Buches darum,
dieses mit den gängigen Elementen einer Abschlussarbeit (u. a. Aufzählungen,
Tabellen und Grafiken) zu füllen.
Das Erstellen von Verzeichnissen (u. a. Literatur-, Abbildungs- und
Tabellenverzeichnis), ein Überblick zu mathematischen Ausdrücken in LaTeX
und ein kleiner Exkurs in die Handhabung von längeren Arbeiten, das Verwenden von mehreren
Dateien und die Versionierung schließen den zweiten Teil ab.
Zuletzt widmet sich der Autor dem Fertigstellen der Arbeit. Neben Schriften
und Besonderheiten bei der Arbeit mit PDF-Dateien gibt es auch einen
Abschnitt zur Fehlersuche, einem Themengebiet, das gerade für Anfänger das
größte Hindernis darstellt.
Das komplette Inhaltsverzeichnis zum Buch ist auf dem dazugehörigen
Webauftritt [2] hinterlegt. Neben einigen
Gratiskapiteln sind hier auch die Minimalbeispiele zu den angesprochen
Bereichen aus dem Buch verfügbar, sodass es dem Leser möglich ist, die
Beispiele ohne lästiges Abtippen des Quellcodes nachzuvollziehen.
Zielgruppe
Wie der Titel des Buches bereits anklingen lässt, sind vor allem
LaTeX-Einsteiger angesprochen. Es werden keine Vorkenntnisse vorausgesetzt
und durch die vielen kurzen Beispiele, die optisch gut zu erkennen sind,
wird praxisorientiert die vorangestellte Theorie erläutert.
Gerade für Studierende der Naturwissenschaften eignet sich das Buch, da auf
viele Vorteile, wie Theoreme und die Definition eigener Umgebungen, relativ
früh im Buch eingegangen wird. Weiterhin wird, für ein Einstiegsbuch
sehr ausführlich, das Erzeugen eigener Grafiken beschrieben.
Für jene Nutzer, denen es bevorsteht, eine längere Arbeit zu schreiben,
werden hilfreiche Hinweise zur technischen Organisation des Vorhabens
gegeben, u. a. wird für die Versionierung Git als Software vorgestellt und
auch auf das Erstellen eines Index wird eingegangen.
Aber auch diejenigen, die bereits erste Schriftstücke in LaTeX gesetzt
haben, bisher jedoch nur nach der Copy&Paste-Methode Quellcodezeilen aus
diversen Foren zusammenkopierten, liefert das Buch einige Aha-Erlebnisse.
Die Abschnitte sind treffend bezeichnet und durch die zahlreichen Beispiele
erkennt man optisch sehr schnell, ob der Abschnitt für die eigene Arbeit
relevant ist oder ob er übersprungen werden kann.
Nicht geeignet ist das Buch für Leser, die LaTeX im Grunde gar nicht
verstehen wollen oder nur eine Universalvorlage für die Arbeit suchen.
Fazit
Das Buch liest sich insgesamt sehr flüssig und liefert einen guten Einstieg
für LaTeX-Neulinge.
Die vielen Hinweise zu Typografie und gutem Textsatz sind sehr hilfreich
und hoffentlich nicht abschreckend für Neulinge. Denn darin sind u. a. auch
die Stärken in der Verwendung von LaTeX zu sehen.
Die wichtigen Pakete werden kurz vorgestellt und wo es nötig ist, wird auf
weiterführende Literatur verwiesen.
An einigen wenigen Stellen weist das Buch noch kleinere Fehler auf, die in
einer 5. redigierten Auflage nicht mehr zu erwarten wären. Der Autor
reagiert auf die Hinweise sehr schnell und eine Auflistung der Anmerkungen
findet sich auf der Internetseite.
Der Preis von knapp 20 Euro scheint gut investiert und gleichgültig, ob das
Buch komplett durchgearbeitet wird oder eher Verwendung als Nachschlagewerk
findet, eine Daseinsberechtigung neben all den anderen LaTeX-Büchern hat es
auf jeden Fall.
Redaktioneller Hinweis: Da es schade wäre, wenn das Buch bei Christina Möller im Regal
verstaubt, wird es verlost. Dazu ist folgende Frage zu beantworten:
„Wer entwickelte LaTeX?“
Die Antwort kann bis zum 8. Juni 2014, 23:59 Uhr über die
Kommentarfunktion oder per E-Mail an redaktion@freiesmagazin.de geschickt
werden. Die Kommentare werden bis zum Ende der Verlosung nicht
freigeschaltet. Das Buch wird unter allen Einsendern, die die Frage richtig
beantworten konnten, verlost.
Links
[1] http://office.microsoft.com/de-de/word/
[2] http://www.latexbuch.de/
[3] http://www.it-fachportal.de/shop/buch/Wissenschaftliche Arbeiten schreiben mit LaTeX/detail.html,b156456
| Buchinformationen |
| Titel | Wissenschaftliche Arbeiten schreiben mit LaTeX: Leitfaden für Einsteiger [3] |
| Autor | Joachim Schlosser |
| Verlag | mitp-Verlag, 2014 |
| Umfang | 328 Seiten |
| ISBN | 978-3826694868 |
| Preis | 19,99 Euro
|
| Autoreninformation |
| Christina Möller
hat während des Studiums die Vorzüge von LaTeX genutzt. Aktuell gehört sie
zu den wenigen, die im Beruf mit LaTeX arbeiten dürfen.
|
Beitrag teilen Beitrag kommentieren
Zum Index
von Dominik Wagenführ
Es gibt sehr viele Bücher darüber, wie „ordentlicher“ Code auszusehen hat,
wobei das teilweise natürlich auch Geschmackssache ist. Robert C. Martin,
der u. a. für sein Buch „Clean Code“ bekannt ist, hat das Konzept auf die
Entwickler ausgeweitet und will ein paar Verhaltensregeln für professionelle
Programmierer geben.
Hinweis: Mit dem Begriff „Entwickler“ in dem Artikel sind sowohl weibliche
als auch männliche Personen gemeint.
Redaktioneller Hinweis: Wir danken dem mitp-Verlag für die Bereitstellung eines Rezensionsexemplares.
Was heißt professionell?
Die Antwort auf diese Frage erfährt man, wenn man das Buch durchgelesen hat.
Martin gibt nicht am Anfang eine klare Definition von „Professionalität“,
sondern zeigt mehrere verschiedene Verhaltensregeln auf und definiert diese
als professionelles Vorgehen.
Worauf baut Martin seine Aussagen? Er selbst schreibt am Anfang des Buches,
dass viele Ratschläge auf seiner persönlichen Erfahrung beruhen. Und davon
hat er genug, schließlich ist er seit 1970 als Programmierer tätig und hat
vermutlich jeden Fehler gemacht, den man in dieser Branche machen kann.
Martin sagt aber auch, dass nicht alle Ratschläge auf jeden passen. Einige
werden sicherlich nur für Kopfschütteln sorgen, aber im Großen und Ganzen
kann jeder etwas aus dem Buch mitnehmen.
Verantwortung: Die Basis der Professionalität
Das Buch beginnt mit einem Unglück. Am 28. Januar 1986 explodierte die
Raumfähre Challenger kurz nach dem
Start [1].
Sieben Menschen kamen dabei ums Leben. Grund für die Explosion war ein
Ausfall der Dichtungsringe zwischen zwei Komponenten, weil es an dem Tag zu
kalt war und die Dichtungsringe nicht für solche niedrigen Temperaturen
ausgelegt waren. Den Ingenieuren der Raumfähre war das Problem bekannt und
sie sprachen auch beim Management vor, um den Start zu verschieben. Das
Management setzte sich aber darüber hinweg, was zu der vorhergesagten
Katastrophe führte.
Was Martin mit dem Beispiel zeigen will, ist dass man als Konstrukteur von
etwas die Verantwortung zu tragen hat. Sei es als Ingenieur oder
Software-Entwickler. Die Verantwortung des Challenger-Unglücks lag
sicherlich auch beim Management, weil sie nicht auf ihre eigenen „Profis“
hörte. Sie lag aber auch bei den Ingenieuren, die sich überstimmen ließen,
obwohl sie diese Katastrophe voraussagen konnten. Was Martin sagen will:
Profis zucken nicht mit den Schultern, wenn sie einen Fehler sehen und
keiner auf sie hört, sondern sie setzen alles daran, dass nichts und niemand
zu Schaden kommt.
Dementsprechend hat jeder Entwickler „seinen“ Code zu verantworten. Er soll
zum einen keinen Schaden am Verhalten zulassen (eine Funktion verhält sich
plötzlich anders als zuvor), aber auch keinen Schaden an der Struktur. Vor
allem der letzte Punkt ist etwas, der bei langjährigen Projekten früher oder
später immer zu einem Problem wird, weil sich die Entwickler nicht daran
halten, z. B. durch Refactorings [2]
für eine klare Struktur zu sorgen.
Testen, testen, testen
Was einen professioneller Entwickler laut Martin auch auszeichnet, ist, dass
er weiß, dass sein Code funktioniert. Und hier bedeutet „wissen“ nicht bloß
„glauben“, sondern er muss es beweisen können. Das geht entweder durch sehr
intensives Code-Studium oder durch Tests, besser noch automatisierte Tests.
Robert C. Martin nennt hier vor allem den Begriff „Test Driven Development“
(kurz TDD [3]).
Darunter versteht man, dass man zuerst den Test schreibt, der scheitert, und
danach den Code, der den Test durchlaufen lässt.
TDD hat dabei noch andere
Vorteile, aber in Bezug auf Professionalität zeigt es, dass der Code
funktioniert und genau das tut, was man von ihm erwartet.
Neben TDD geht Martin noch auf andere Teststrategien wie Akzeptanztests ein,
denen ebenfalls ein eigenes Kapitel gewidmet ist.
Profis sind Teamplayer
Wer heute eine Stellenausschreibung für einen Job als Software-Entwickler
anschaut, wird das Wörtchen „Teamarbeit“ so gut wie immer lesen. Nach Martin
sind die meisten Entwickler zwar eher Einzelgänger und haben lieber mit
abstrakten Problemen als mit Menschen zu tun, aber man kommt normalerweise
auch nicht darum herum, mit anderen Leuten zusammenzuarbeiten.
Hier stellt Martin heraus, dass ein Teamplayer nicht zu allem Ja und
Amen sagt, sondern alles daran setzt, dass das Team als Ganzes vorwärts kommt.
Hierzu gehört eine klare Kommunikation mit dem Management und Kollegen. Wer
kennt es nicht, dass der Software-Manager oder Product Owner auf einen
zukommt und fragt: „Schaffst Du das bis nächste Woche Dienstag?“ und man
antwortet: „Ich versuch's.“ In der Regel antwortet man nur so schwammig,
weil man sich nicht sicher ist bzw. sich sogar sicher ist, es nicht zu
schaffen, aber nicht Nein sagen will.
Der Software-Manager oder Product
Owner hört aber aus dieser Aussage eher ein „Ja, das ist machbar.“ heraus.
Man sollte also grundsätzlich klar ansagen, was möglich ist und was nicht.
Und man sollte auch grundsätzlich nichts bloß versuchen. Oder wie Yoda schon
sagte [4]: „Tu es oder tu es nicht. Es gibt kein Versuchen.“
Zum Teamwork gehört es aber auch, Hilfe anzubieten, wenn man sieht, dass
jemand irgendwo hängt. Ebenso sollte man sich Zeit für Kollegen nehmen, die
eine Frage haben. Das muss ja nicht unbedingt sofort sein,
aber fünfzehn Minuten später ist ja auch okay.
Auf der anderen Seite sollte man in einem Team auch
nicht zögern, um Hilfe zu bitten. Viele Menschen denken, dass Fragen ein
Zeichen von Schwäche ist. Ganz im Gegenteil ist Fragen menschlich,
denn niemand weiß alles. Anstatt eine Woche alleine an einem Problem zu knabbern,
ist es sinnvoller, jemanden zu
fragen, der die Antwort in zehn Minuten parat hat.
Zeiteinteilung und Stichtage
Zur korrekten Kommunikation mit dem Management zählt laut Martin auch, dass
man Aufwände richtig abschätzt. Wie der Ausdruck „Aufwandsabschätzung“
aussagt, handelt es sich dabei um keine definitive Zusage, was allen
Beteiligten klar sein sollte. Es kann mal kürzer oder mal länger dauern.
Aus diesem Grund gibt Martin verschiedene Schätztechniken an. So werden zum
einen das aus der Agilen Entwicklung bekannte „Planning Poker“ genannt, was
auf der Delphi-Methode basiert [5].
Zum anderen wird aber auch PERT erwähnt, was für Program Evaluation and
Review Technique
steht [6].
Die Besonderheit ist hier, dass man die Schätzung nicht als einfache Zahl
angibt, sondern als eine Art Mittel aus Bestfall, Normalfall und schlimmsten
Fall. Hiervon berechnet Martin auch noch die Standardabweichung, um so die
Abweichung für den Schlechtfall einzukalkulieren.
Damit man seine Aufgaben ordentlich und zeitgemäß erfüllen kann, gehört auch
eine Zeiteinteilung. Zeitmanagement ist für einen Entwickler normalerweise
sehr wichtig, da er viele Aufgaben „gleichzeitig“ bearbeiten oder zumindest
im Kopf halten muss. Darauf wird in einem eigenen Kapitel auch eingegangen,
was sich unter anderem dem leidigen Thema der Meetings widmet. Laut Martin
ist es okay, ein Meeting frühzeitig zu verlassen (oder erst gar nicht
teilzunehmen), wenn man nicht mehr benötigt wird. Vor allem die Aussagen,
dass es die Pflicht des Vorgesetzten ist, dem Entwickler Meetings zu
ersparen, ist interessant, denn oft sind es genau die Vorgesetzten, die
einen zu diesen Meetings „ermuntern wollen“ (um es positiv auszudrücken).
Fazit
Lernt man durch das Buch, ein professioneller Programmierer zu werden? Hier
kann man ein ganz deutliches und klares „Vielleicht“ als Antwort geben.
Grund für diese ausweichende Antwort ist, dass das Wort Professionalität
nicht fest von der Welt definiert ist. Robert C. Martin gibt seine
Einschätzung, was er unter Professionalität versteht und wie man diese
erreichen kann.
Unter dem Gesichtspunkt kann man zum Buch aber zumindest sagen, dass es
wirklich sehr viele hilfreiche Tipps enthält, wie man ein besserer
Programmierer werden kann. Angefangen bei der Verantwortung, die man für den
Code hat, bis hin zu einer störungsfreien Kommunikation zwischen allen
Parteien.
Interessant ist auch, dass Martin das Thema Karriere und Fortbildung in die
Hände der Entwickler legt. Sicherlich hat auch eine Firma Interesse daran,
seine Entwickler weiter auszubilden, um neuen Anforderungen gewachsen zu
sein.
(Aus einem anderen Buch zwischen zwei Managern: „Was ist denn, wenn
wir unsere Leute teuer weiterbilden und sie dann den Job wechseln?“ – „Was
ist, wenn wir sie nicht weiterbilden und sie bleiben?“)
Aber Martin sieht es
als Pflicht eines professionellen Programmierers an, sich auch privat
weiterzubilden. Sei es durch kleine Fingerübungen am heimischen PC (am
besten in einer Sprache, die man nicht täglich nutzt), bis hin zu
Mentorenarbeit oder Hilfe in einem Open-Source-Projekt.
(Martin selbst zeigt
sich zum Beispiel für das Open-Source-Testing-Framework
FitNesse [7] verantwortlich.)
Schön ist die klare Gliederung des Buches, deren Kapitel nicht aufeinander
aufbauen. So kann man sehr leicht auch nur ein einzelnes Thema durchlesen
oder etwas nachlesen, wenn es einen interessiert. Ebenfalls gut sind die
Beispiele im Buch, die sehr oft als Gespräch zwischen zwei oder drei
Beteiligten dargestellt werden. Nach einem Gespräch analysiert Martin dann,
was und wie es gesagt wurde und wo es ggf. zu Problemen bei der Kommunikation kam.
Das ist sehr anschaulich und verständlich, da fast jeder schon ähnliche
Gespräche gehabt hat.
Eine Besonderheit, die es abschließend noch hervorzuheben gilt ist, dass
Robert C. Martin sich gegen den
Flow-Zustand [8]
ausspricht. Das ist insoweit besonders, da fast alle Programmierbücher
propagieren, dass man genau in diesem Zustand bessere Arbeit leistet. Martin
ist ein Gegner dieses Flows und versucht alles, nicht dort hineinzukommen
bzw. darin zu bleiben, weil man in dem Zustand zwar produktiver ist, aber
auch Teile seines Gehirns für rationales Denken ausschaltet und somit eher
Fehler macht.
Alles in allem ist „Clean Coder“ ein sehr schönes Buch, das, wenn es einen
vielleicht auch nicht gleich professionell werden lässt, zumindest Tipps und
Regeln an die Hand gibt, wie man ein besserer Programmierer werden kann.
Redaktioneller Hinweis: Da es schade wäre, wenn das Buch bei Dominik Wagenführ im Regal
verstaubt, wird es verlost. Dazu ist folgende Frage zu beantworten:
„Wie lautet der Spitzname von Robert C. Martin?“
Die Antwort kann bis zum 8. Juni 2014, 23:59 Uhr über die
Kommentarfunktion oder per E-Mail an redaktion@freiesmagazin.de geschickt
werden. Die Kommentare werden bis zum Ende der Verlosung nicht
freigeschaltet. Das Buch wird unter allen Einsendern, die die Frage richtig
beantworten konnten, verlost.
| Buchinformationen |
| Titel | Clean Coder [9] |
| Autor | Robert C. Martin (übersetzt von Jürgen Dubau) |
| Verlag | mitp-Verlag, 2014 |
| Umfang | 216 Seiten |
| ISBN | 978-3-8266-9695-4 |
| Preis | 34,99 € (Druck), 29,99 € (EPUB/PDF)
|
Links
[1] https://de.wikipedia.org/wiki/STS-51-L#Das_Challenger-Ungl.C3.BCck
[2] https://de.wikipedia.org/wiki/Refactoring
[3] https://de.wikipedia.org/wiki/Testgetriebene_Entwicklung
[4] http://www.jedipedia.de/wiki/Yoda
[5] https://de.wikipedia.org/wiki/Aufwandsschätzung_(Softwaretechnik)#Delphi-Methode_oder_Sch.C3.A4tzklausur
[6] https://de.wikipedia.org/wiki/Program_Evaluation_and_Review_Technique
[7] http://www.fitnesse.org/
[8] https://de.wikipedia.org/wiki/Flow_(Psychologie)
[9] http://www.it-fachportal.de/shop/buch/Clean Coder/detail.html,b191159
| Autoreninformation |
| Dominik Wagenführ (Webseite)
ist Software-Entwickler und hat in dem Buch ein paar gute Tipps gefunden,
die ihm bei seiner Arbeit helfen können.
|
Beitrag teilen Beitrag kommentieren
Zum Index
Für Leserbriefe steht unsere E-Mailadresse
zur Verfügung - wir freuen uns über Lob,
Kritik und Anregungen zum Magazin.
An dieser Stelle möchten wir alle Leser ausdrücklich ermuntern,
uns auch zu schreiben, was nicht so gut gefällt. Wir bekommen
sehr viel Lob (was uns natürlich freut), aber vor allem durch
Kritik und neue Ideen können wir uns verbessern.
Leserbriefe und Anmerkungen
Linux auf dem Laptop (Acer Aspire V3-771G)
->
Danke für den Beitrag. Ich vermisse WLAN als Punkt. Gerade bei Linux
Mint 16 Mate bzw. Ubuntu habe ich Probleme mit dem Broadcom-Treiber.
Die Installation des Systems klappt, die Treiberinstallation aber erst
nach einigen Anläufen. Hat man die Kiste am Laufen, sollte man ja immer
gleich ein Update machen. Hinterher war WLAN wieder tot.
Das geht seit einigen Monaten mit verschiedenen Ubuntu-Derivaten so.
Auch habe ich einige Systeme mit einem Update zerschossen, wo dann
plötzlich die Grafik weg war oder Kernel-Panic kam. Egal ob Mate,
Cinnamon, KDE.
Hilfreich wäre, diese Randerscheinungen, die vielleicht nicht ganz zum
Thema passen, mit zu erwähnen. Vielleicht ärgert sich mancher User mit
ähnlichen Themen rum und hasst es, wenn Linux immer hoch gelobt wird.
Ich bin dazu übergegangen, Konfigurationen erst anzugehen, wenn ein
System alle Softwareinstallationen und einige Updates überlebt hat.
Übrigens sterben auch andere Linux-Distributionen durch Updates.
Bitte beim nächsten Artikel auf eine stabile Distribution setzen und
nicht einfach auf die möglicherweise falsche Rangliste bei Distrowatch
gucken.
Olaf G. (Kommentar)
<-
Es gibt sicherlich auf verschiedenen Laptops immer schon mal wieder
frustreiche Probleme mit spezieller Hardware. Breite und detaillierte
Troubleshooting-Informationen in Bezug auf bestimmte Modelle und
Distributionen findet man meistens im
Linux-Laptop-Wiki [1].
Daniel Stender
->
Sehr schöner Artikel. Ich habe selbst schon mehrere Distributionen auf
Acer-Laptops installiert (aktuell Mageia 4 auf Acer Travelmate
P253" M. Sicher gibt es keine Garantie, dass jede Distribution auf
jedem Acer auch läuft. Hier sollte man sich vorher informieren.
Ein Problem konnte ich bisher nicht lösen: Einstellen der Helligkeit.
Ich wüsste gerne, ob das für den Autor auch ein Problem war. Im
Artikel steht leider nichts dazu.
Stefan Horn (Kommentar)
<-
Danke für das Lob. Die Bildschirmhelligkeit einzustellen über
„Einstellungen -> Leistung“ auf Gnome3 funktioniert hier mit
aktuellem Debian Testing auf dem Core i7-771G einwandfrei, dasselbe
gilt auch für das Abdunkeln mit xbacklight. Das mag aber, wie auch das
neulich reingekommene Update mit dem sich endlich das „Click-on-Tap“
des Touchpads über die Gnome3- Einstellungen auch abstellen lässt, eine
neuere Entwicklung sein.
Daniel Stender
BeagleBone und tmux
->
Mich intessiert sehr der Titel „BeagleBone Black“. Ich hoffe, mehr
Informationen darüber zu bekommen.
Für Japaner ist es sehr komisch, dass die zwei Wörter „Kung-Fu“ und
„Ninja“ zusammen angezeigt werden: „Kung-fu“ ist chinesisch, und
„Ninja“ ist japanisch.
Tsuyoshi Sakaguchi
<-
Zum BeagleBone werden wir außer der Rezension des Gerätes und des
Buches vorerst wohl nicht mehr veröffentlichten. Sollte ich mich weiter
mit dem Gerät beschäftigen, könnte ich ggf. noch einen weiteren Artikel
dazu schreiben.
Ihre Anmerkung bzgl. Ninja und Kung-Fu werde ich an den Autor des
Artikels weiterleiten. Ich gehe davon aus, dass er einfach nur zwei
interessant klingende, asiatische Wörter in seine Überschrift
einbringen wollte.
Dominik Wagenführ
Empfehlen-Links im Magazin
->
Ich bin über Android jetzt bei Ubuntu eingestiegen und so auf euer
Magazin gestoßen. Da ich meine Tageszeitung schon im EPUB-Format lese,
fand ich es zusätzlich interessant, dass ihr auch EPUB's publiziert.
Ich lese fast alles mit weißer Schrift auf schwarzem Hintergrund, da
sich das als viel augenfreundlicher erwiesen hat (Moon Reader).
Ich habe euer Magazin verschlungen und hatte bei einem Link sogar eine
echte Mail vom großen Meister Thorwald Linux vor mir … wow und Danke!
Ich mag eure einfache und kurze Sprache: kurzen Hauptsätze, starke
Verben und viel Persönlichkeit. Nochmal Danke! Ihr habt, wenn ich bei
Ubuntu bleibe, woran ich leider zweifele, einen regelmäßigen Leser
gewonnen.
Nun zu meinem Verbesserungsvorschlag, den ich übrigens auch an alle
e-Reader-Programmierer sende:
Ich hätte gerne am Ende jedes Artikels die
Möglichkeit, den Artikel als Mail zu senden und weiterzuempfehlen mit
einem Button. Dieses ewige Copy&Paste und der App-Wechsel gehen mir
auf den Keks. So habe ich es unterlassen …
Mat Philips
<-
Die Idee mit dem „Empfehlen“-Button haben wir für sehr sinnvoll gehalten
und dazu auch einen kleinen Wettbewerb
ausgeschrieben [2].
Alle eingereichten Icons können Sie übrigens auch auf der
freiesMagazin-Webseite [3]
betrachten. Wie im Editorial zu dieser Ausgabe beschrieben, finden Sie
von nun an am Ende jeder Ausgabe zwei Icons mit Links, die es dem Leser
ermöglichen, den Artikel per E-Mail weiterzuempfehlen oder auf unserer
Webseite zu kommentieren.
Matthias Sitte
<-
Bzgl. Ubuntu: Es gibt noch 1000 andere Linux-Distributionen in der
Welt, testen sie doch eine bzw. mehren von diesen. freiesMagazin beschränkt
sich nicht auf Ubuntu, sondern umfasst alle Linux- und
Open-Source-Themen jeglicher Art.
Dominik Wagenführ
Artikelwünsche
->
Vielen Dank für die Leserbriefe, besonders für den über die pyladies.
Ich hatte den komplett überlesen. Obwohl ich teilweise auch nicht
direkt verstehe, was uns die gute Frau da sagen will.
Noch einen Tip: Kann jemand mal CAELinux testen? Ist für Wissenschaftler.
Matthias Kühmsted
<-
Wir nehmen gerne CAELinux mit auf unsere
Wunschliste [4].
Allerdings können wir nicht versprechen, einen Artikel über CAELinux
zu veröffentlichen.
Da freiesMagazin keine feste Autorenmannschaft hat, sind wir auf Zusendungen
aus der Community angewiesen. Dabei gilt: (Fast) Jeder kann einen
Artikel über das schreiben, was ihn interessiert. Dazu möchten wir
unsere Leser hiermit gerne ermutigen!
Als Autor sollte man natürlich Spaß am Schreiben haben und sich
verständlich ausdrücken können, sodass jeder Leser den Artikel oder die
Anleitungen nachvollziehen kann. Alle Artikel werden von der Redaktion
vor einer Veröffentlichung durchgelesen und wir versuchen Tipps zu
geben, was man noch verbessern kann, damit die Leser des Artikels
später auch Spaß beim Lesen haben.
Wenn Sie nun Lust bekommen haben, einen Artikel für freiesMagazin zu schreiben,
dann senden Sie uns doch eine E-Mail an oder nehmen Sie über
das Kontakt-Formular [5] mit uns
Kontakt auf.
Dominik Wagenführ
Links
[1] http://www.linlap.com/
[2] http://www.freiesmagazin.de/20140501-wettbewerb-neue-icons-fuers-magazin-gesucht
[3] http://www.freiesmagazin.de/20140524-gewinner-des-icon-wettbewerbs
[4] http://www.freiesmagazin.de/artikelwuensche
[5] http://www.freiesmagazin.de/kontakt
Die Redaktion behält sich vor, Leserbriefe gegebenenfalls zu
kürzen. Redaktionelle Ergänzungen finden sich in eckigen Klammern.
Beitrag teilen Beitrag kommentieren
Zum Index
(Alle Angaben ohne Gewähr!)
Sie kennen eine Linux-Messe, welche noch nicht auf der Liste zu
finden ist? Dann schreiben Sie eine E-Mail mit den Informationen zu
Datum und Ort an .
Zum Index
freiesMagazin erscheint am ersten Sonntag eines Monats. Die Juli-Ausgabe
wird voraussichtlich am 6. Juli u. a. mit folgenden Themen veröffentlicht:
- Statische Webseiten mit Pelican erstellen
- Typographie lernen mit Type:Rider
- Planet Explorers
- Registerhaltiger Satz mit LaTeX
Es kann leider vorkommen, dass wir aus internen Gründen angekündigte Artikel verschieben müssen. Wir bitten dafür um Verständnis.
Zum Index
An einigen Stellen benutzen wir Sonderzeichen mit einer bestimmten
Bedeutung. Diese sind hier zusammengefasst:
| $: | Shell-Prompt |
| #: | Prompt einer Root-Shell – Ubuntu-Nutzer können
hier auch einfach in einer normalen Shell ein
sudo vor die Befehle setzen. |
| ~: | Abkürzung für das eigene Benutzerverzeichnis
/home/BENUTZERNAME |
Zum Index
freiesMagazin erscheint als PDF, EPUB und HTML einmal monatlich.
Erscheinungsdatum: 1. Juni 2014
Erstelldatum: 22. Juni 2014
Dieses Magazin wurde mit LaTeX erstellt. Mit vollem Namen
gekennzeichnete Beiträge geben nicht notwendigerweise die Meinung
der Redaktion wieder. Wenn Sie freiesMagazin ausdrucken möchten, dann
denken Sie bitte an die Umwelt und drucken Sie nur im Notfall. Die
Bäume werden es Ihnen danken. ;-)
Soweit nicht anders angegeben, stehen alle Artikel, Beiträge und Bilder in
freiesMagazin unter der Creative-Commons-Lizenz CC-BY-SA 4.0 International. Das Copyright liegt
beim jeweiligen Autor.
Die Kommentar- und Empfehlen-Icons wurden von Maren Hachmann erstellt
und unterliegen ebenfalls der Creative-Commons-Lizenz CC-BY-SA 4.0 International.
freiesMagazin unterliegt als Gesamtwerk
der Creative-Commons-Lizenz CC-BY-SA 4.0 Unported mit Ausnahme der
Inhalte, die unter einer anderen Lizenz hierin veröffentlicht
werden. Das Copyright liegt bei Dominik Wagenführ. Es wird erlaubt,
das Werk/die Werke unter den Bestimmungen der Creative-Commons-Lizenz
zu kopieren, zu verteilen und/oder zu modifizieren.
Die xkcd-Comics stehen separat unter der Creative-Commons-Lizenz CC-BY-NC 2.5 Generic. Das Copyright liegt
bei Randall Munroe.
Zum Index
File translated from
TEX
by
TTH,
version 3.89.
On 22 Jun 2014, 09:37.